Archive for category tags
Are these the angriest tracks on the web?
I built a playlist of songs that most frequently appear in playlists with the words angry or mad with the Smart Playlist Builder. These are arguably some of the angriest tracks on the web.
http://www.rdio.com/people/plamere/playlists/5779446/Top_angry_songs_created_with_SPB/
It is interesting to compare these angry tracks to the top tracks tagged with angry at Last.fm.
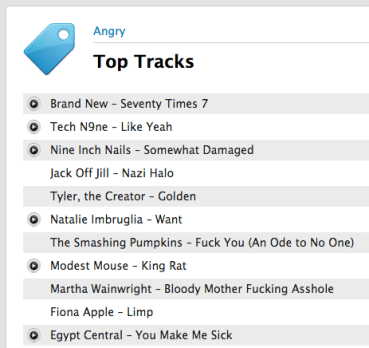
I can’t decide whether the list derived from angry playlists is better or worse than the list driven by social tags. I’d love to hear your opinion. Take a look at these two lists and tell me which list is a better list of angry tracks and why.
yep, this is totally unscientific poll, but I’m still interested in what you think.
Map of Music Styles
Posted by Paul in code, data, events, fun, tags, The Echo Nest, visualization on April 22, 2012
I spent this weekend at Rethink Music Hackers’ Weekend building a music hack called Map of Music Styles (aka MOMS). This hack presents a visualization of over 1000 music styles. You can pan and zoom through the music space just like you can with Google maps. When you see an interesting style of music you can click on it to hear some samples of music of that style.

It is fun to explore all the different neighborhoods of music styles. Here’s the Asian corner:

Here’s the Hip-Hop neighborhood:

And a mega-cluster of ambient/chill-out music:

To build the app, I collected the top 2,000 or so terms via The Echo Nest API. For each term I calculated the most similar terms based upon artist overlap (for instance, the term ‘metal’ and ‘heavy metal’ are often applied to the same artists and so can be considered similar, where as ‘metal’ and ‘new age’ are rarely applied to the same artist and are, therefore, not similar). To layout the graph I used Gephi (Its like Photoshop for graphs) and exported the graph to SVG. After that it was just a bit of Javascript, HTML, and CSS to create the web page that will let you pan and zoom. When you click on a term, I fetch audio that matches the style via the Echo Nest and 7Digital APIs.
There are a few non-styles that snuck through – the occasional band name, or mood, but they don’t hurt anything so I let them hang out with the real styles. The app works best in Chrome. There’s a bug in the Firefox version that I need to work out.
Give it a try and let me know how you like it: Map of Music Styles
The Labyrinth of Genre
Posted by Paul in code, data, tags, The Echo Nest, visualization on January 16, 2011
I’m fascinated with how music genres relate to each other, especially how one can use different genres as stepping stones as a guide through the vast complexities of music. There are thousands of genres, some like rock or pop represent thousands of artists, while some like Celtic Metal or Humppa may represent only a handful of artists. Building a map by hand that represents the relationships of all of these genres is a challenge. Is Thrash Metal more closely related to Speed Metal or to Power Metal? To sort this all out I’ve built a Labyrinth of Genre that lets you explore the many genres. The Labyrinth lets you wander though about a 1000 genres, listening to samples from representative artists.

Click on a genre and the labyrinth will be expanded to show similar half a dozen similar genres and you’ll hear songs in the genre.
I built the labyrinth by analyzing a large collection of last.fm tags. I used the cosine distance of tf-idf weighted tagged artists as a distance metric for tags. When you click on a node, I attach the six closest tags that haven’t already been attached to the graph. I then use the Echo Nest APIs to get all the media.
Even though it’s a pretty simple algorithm, it is quite effective in grouping similar genre. If you are interested in wandering around a maze of music, give the Labyrinth of Genre a try.
A Genre Map
Inspired by an email exchange with Samuel Richardson, creator of ‘Know your genre‘ I created a genre map that might serve as a basis for a visual music explorer (perhaps something to build at one of the upcoming music hack days). The map is big and beautiful (in a geeky way). Here’s an excerpt, click on it to see the whole thing.

Update – I’ve made an interactive exploration tool that lets you wander through the genre graph. See the Labyrinth of Genre

Update 2 – Colin asked the question “What’s the longest path between two genres?” – If I build the graph by using the 12 nearest neighbors to each genre, find the minimum spanning tree for that graph and then find the longest path, I find this 31 step wonder:

Of course there are lots of ways to skin this cat – if I build the graph with just the nearest 6 neighbors, and don’t extract the minimum spanning tree, the longest path through the graph is 10 steps:

LastFM-ArtistTags2007
A few years back I created a data set of social tags from Last.fm. RJ at Last.fm graciously gave permission for me to distribute the dataset for research use. I hosted the dataset on the media server at Sun Labs. However, with the Oracle acquisition, the media server is no longer serving up the data, so I thought I would post the data elsewhere.
The dataset is now available for download here: Lastfm-ArtistTags2007
Here are the details as told in the README file:
The LastFM-ArtistTags2007 Data set
Version 1.0
June 2008
What is this?
This is a set of artist tag data collected from Last.fm using
the Audioscrobbler webservice during the spring of 2007.
The data consists of the raw tag counts for the 100 most
frequently occuring tags that Last.fm listeners have applied
to over 20,000 artists.
An undocumented (and deprecated) option of the audioscrobbler
web service was used to bypass the Last.fm normalization of tag
counts. This data set provides raw tag counts.
Data Format:
The data is formatted one entry per line as follows:
musicbrainz-artist-id<sep>artist-name<sep>tag-name<sep>raw-tag-count
Example:
11eabe0c-2638-4808-92f9-1dbd9c453429<sep>Deerhoof<sep>american<sep>14
11eabe0c-2638-4808-92f9-1dbd9c453429<sep>Deerhoof<sep>animals<sep>5
11eabe0c-2638-4808-92f9-1dbd9c453429<sep>Deerhoof<sep>art punk<sep>21
11eabe0c-2638-4808-92f9-1dbd9c453429<sep>Deerhoof<sep>art rock<sep>18
11eabe0c-2638-4808-92f9-1dbd9c453429<sep>Deerhoof<sep>atmospheric<sep>4
11eabe0c-2638-4808-92f9-1dbd9c453429<sep>Deerhoof<sep>avantgarde<sep>3
Data Statistics:
Total Lines: 952810
Unique Artists: 20907
Unique Tags: 100784
Total Tags: 7178442
Filtering:
Some minor filtering has been applied to the tag data. Last.fm will
report tag with counts of zero or less on occasion. These tags have
been removed.
Artists with no tags have not been included in this data set.
Of the nearly quarter million artists that were inspected, 20,907
artists had 1 or more tags.
Files:
ArtistTags.dat - the tag data
README.txt - this file
artists.txt - artists ordered by tag count
tags.txt - tags ordered by tag count
License:
The data in LastFM-ArtistTags2007 is distributed with permission of
Last.fm. The data is made available for non-commercial use only under
the Creative Commons Attribution-NonCommercial-ShareAlike UK License.
Those interested in using the data or web services in a commercial
context should contact partners at last dot fm. For more information
see http://www.audioscrobbler.net/data/
Acknowledgements:
Thanks to Last.fm for providing the access to this tag data via their
web services
Contact:
This data was collected, filtered and by Paul Lamere of The Echo Nest. Send
questions or comments to Paul.Lamere@gmail.com
Social Tags and Music Information Retrieval
Posted by Paul in Music, music information retrieval, research, tags on May 11, 2009
It is paper writing season with the ISMIR submission deadline just four days away. In the last few days a couple of researchers have asked me for a copy of the article I wrote for the Journal of New Music Research on social tags. My copyright agreement with the JNMR lets me post a pre-press version of the article – so here’s a version that is close to what appeared in the journal.
Social Tagging and Music Information Retrieval
Abstract
Social tags are free text labels that are applied to items such as artists, albums and songs. Captured in these tags is a great deal of information that is highly relevant to Music Information Retrieval (MIR) researchers including information about genre, mood, instrumentation, and quality. Unfortunately there is also a great deal of irrelevant information and noise in the tags.
Imperfect as they may be, social tags are a source of human-generated contextual knowledge about music that may become an essential part of the solution to many MIR problems. In this article, we describe the state of the art in commercial and research social tagging systems for music. We describe how tags are collected and used in current systems. We explore some of the issues that are encountered when using tags, and we suggest possible areas of exploration for future research.
Here’s the reference:
Paul Lamere. Social tagging and music information retrieval. Journal of New Music Research, 37(2):101–114.
Last.fm’s new player
Posted by Paul in Music, recommendation, tags on May 6, 2009
Last.fm pushed out a new web-based music player that has some nifty new features including an artist slideshow, multi-tag radio and multi-artist radio. It is pretty nice.

I like the new artist slide show (it is very Snapp Radio like), but they seem to run out of unique artist images rather quickly – and what’s with the grid? It looks like I am looking at the artists through a screen window.
I really like the multi-tag radio, but it is not 100% clear to me whether it is finding music that has been tagged with all the tags or whether it just alternates between the tags. Hopefully it is the former. Update: It is the former.

It is nice to see Multi-tag radio come out of the playground and into the main Last.fm player. It is a great way to get a much more fined-tuned listening experience. I do worry that Last.fm is de-emphasizing tags though. They only show a couple of tags in the player and it is hard to tell whether these are artist, album or track tags. Last.fm’s biggest treasure trove is their tag data, so they should be very careful to avoid any interface tweaks that may reduce the number of tags they collect.
The BPM Explorer
Posted by Paul in code, fun, java, processing, startup, tags, The Echo Nest, Uncategorized, visualization, web services on April 9, 2009
Last month I wrote about using the Echo Nest API to analyze tracks to generate plots that you can use to determine whether or not a machine is responsible for setting the beat of a song. I received many requests to analyze tracks by particular artists, far too many for me to do without giving up my day job. To satisfy this pent up demand for click track analysis I’ve written an application called the BPM Explorer that you let you create your own click plots. With this application you can analyze any song in your collection, view its click plot and listen to your music, synchronized with the plot. Here’s what the app looks like:

Check out the application here: The Echo Nest BPM Explorer. It’s written in Processing and deployed with Java Webstart, so it (should) just work.
My primary motiviation for writing this application was to check out the new Echo Nest Java Client to make sure that it was easy to use from Processing. One of my secret plans is to get people in the Processing community interested in using the Echo Nest API. The Processing community is filled with some ultra-creative folks that have have strong artistic, programming and data visualization skills. I’d love to see more song visualizations like this and this that are built using the Echo Nest APIs. Processing is really cool – I was able to write the BPM explorer in just a few hours (it took me longer to remember how to sign jar files for webstart than it did to write the core plotter). Processing strips away all of the boring parts of writing graphic programming (create a frame, lay it out with a gridbag, make it visible, validate, invalidate, repaint, paint arghh!). For processing, you just write a method ‘draw()’ that will be called 30 times a second. I hope I get the chance to write more Processing programs.
Update: I’ve released the BPM Explorer code as open source – as part of the echo-nest-demos project hosted at google-code. You can also browse the read for the BPM Explorer.
Music discovery is a conversation not a dictatorship
Posted by Paul in Music, recommendation, research, tags on April 3, 2009
Two big problems with music recommenders: (1) They can’t tell me why they recommended something beyond the trivial “People who liked X also liked Y” and (2) If I want to interact with a recommender I’m all thumbs – I can usually give a recommendation a thumbs up or thumbs down but there is no way to use steer the recommender (“no more emo please!”). These problems are addressed in The Music Explaura – a web-based music exploration tool just released by Sun Labs.
The Music Explaura lets you explore the world of music artists. If gives you all the context you need – audio, artist bio, videos, photos, discographies to help you decided whether or not a particular artist is interesting. The Explaura also gives you similar-artist style recommendations. For any artist, you are given a list of similar artists for you to explore. The neat thing is, for any recommended artist, you can ask why that artist was recommended and the Explaura will give you an explanation of why that artist was recommended (in the form of an overlapping tag cloud).

The really cool bit (and this is the knock your socks off type of cool) is that you can use an artists tag cloud to steer the recommender. If you like Jimi Hendrix, but want to find artists that are similar but less psychedelic and more blues oriented, you can just grab the ‘psychedelic’ tag with your mouse and shrink it and grab the ‘blues’ tag and make it bigger – you’ll instantly get an updated set of artists that are more like Cream and less like The Doors.

I strongly suggest that you go and play with the Explaura – it lets you take an active role in music exploration. What’s a band that is an emo version of Led Zeppelin? Blue Öyster Cult of course! What’s an artist like Britney Spears but with an indie vibe? Katy Perry! How about a band like The Beatles but recording in this decade? Try The Coral. A band like Metallica but with a female vocalists? Try Kittie. Was there anything like emo in the 60s? Try Leonard Cohen. The interactive nature of the Explaura makes it quite addicting. I can get lost for hours exploring some previously unknown corner of the music world.
Steve (the search guy) has a great post describing the Music Explaura in detail. One thing he doesn’t describe is the backend system architecture. Behind the Music Explaura is a distributed data store with item search and and similarity capabilities built into the core. This makes scaling the system up to millions of items with requests from thousands of simultaneous users possible. It really is a nice system. (Full disclosure here: I spent the last several years working on this project – so naturally I think it is pretty cool).
The Music Explaura gives us a hint of what music discovery will be like in the future. Instead of a world where a music vendor gives you a static list of recommended artists we’ll live in a world where the recommender can tell you why it is recommending an item, and you can respond by steering the recommendations away from things you don’t like and toward the things that you do like. Music discovery will no longer be a dictatorship, it will be a two-way conversation.
Magnatagatune – a new research data set for MIR
Posted by Paul in data, Music, music information retrieval, research, tags, The Echo Nest on April 1, 2009

Edith Law (of TagATune fame) and Olivier Gillet have put together one of the most complete MIR research datasets since uspop2002. The data (with the best name ever) is called magnatagatune. It contains:
- Human annotations collected by Edith Law’s TagATune game.
- The corresponding sound clips from magnatune.com, encoded in 16 kHz, 32kbps, mono mp3. (generously contributed by John Buckman, the founder of every MIR researcher’s favorite label Magnatune)
- A detailed analysis from The Echo Nest of the track’s structure and musical content, including rhythm, pitch and timbre.
- All the source code for generating the dataset distribution
Some detailed stats of the data calculated by Olivier are:
- clips: 25863
- source mp3: 5405
- albums: 446
- artists: 230
- unique tags: 188
- similarity triples: 533
- votes for the similarity judgments: 7650
This dataset is one stop shopping for all sorts of MIR related tasks including:
- Artist Identification
- Genre classification
- Mood Classification
- Instrument identification
- Music Similarity
- Autotagging
- Automatic playlist generation
As part of the dataset The Echo Nest is providing a detailed analysis of each of the 25,000+ clips. This analysis includes a description of all musical events, structures and global attributes, such as key, loudness, time signature, tempo, beats, sections, and harmony. This is the same information that is provided by our track level API that is described here: developer.echonest.com.
Note that Olivier and Edith mention me by name in their release announcement, but really I was just the go between. Tristan (one of the co-founders of The Echo Nest) did the analysis and The Echo Nest compute infrastructure got it done fast (our analysis of the 25,000 tracks took much less time than it did to download the audio).
I expect to see this dataset become one of the oft-cited datasets of MIR researchers.
Here’s the official announcement:
Edith Law, John Buckman, Paul Lamere and myself are proud to announce the release of the Magnatagatune dataset.
This dataset consists of ~25000 29s long music clips, each of them annotated with a combination of 188 tags. The annotations have been collected through Edith’s “TagATune” game (http://www.gwap.com/gwap/gamesPreview/tagatune/). The clips are excerpts of songs published by Magnatune.com – and John from Magnatune has approved the release of the audio clips for research purposes. For those of you who are not happy with the quality of the clips (mono, 16 kHz, 32kbps), we also provide scripts to fetch the mp3s and cut them to recreate the collection. Wait… there’s more! Paul Lamere from The Echo Nest has provided, for each of these songs, an “analysis” XML file containing timbre, rhythm and harmonic-content related features.
The dataset also contains a smaller set of annotations for music similarity: given a triple of songs (A, B, C), how many players have flagged the song A, B or C as most different from the others.
Everything is distributed freely under a Creative Commons Attribution – Noncommercial-Share Alike 3.0 license ; and is available here: http://tagatune.org/Datasets.html
This dataset is ever-growing, as more users play TagATune, more annotations will be collected, and new snapshots of the data will be released in the future. A new version of TagATune will indeed be up by next Monday (April 6). To make this dataset grow even faster, please go to http://www.gwap.com/gwap/gamesPreview/tagatune/ next Monday and start playing.
Enjoy!
The Magnatagatune team

{kind=link}