Archive for category genre
How the Autocanonizer works
Posted by Paul in code, data, events, fun, genre, hacking, music hack day, The Echo Nest on March 18, 2014
Last week at the SXSW Music Hack Championship hackathon I built The Autocanonizer. An app that tries to turn any song into a canon by playing it against a copy of itself. In this post, I explain how it works.
At the core of The Autocanonizer are three functions – (1) Build simultaneous audio streams for the two voices of the canon (2) Play them back simultaneously, (3) Supply a visualization that gives the listener an idea of what is happening under the hood. Let’s look at each of these 3 functions:
(1A) Build simultaneous audio streams – finding similar sounding beats
The goal of the Autocanonizer is to fold a song in on itself in such a way that the result still sounds musical. To do this, we use The Echo Nest analyzer and the jremix library to do much of the heavy lifting. First we use the analyzer to break the song down into beats. Each beat is associated with a timestamp, a duration, a confidence and a set of overlapping audio segments. An audio segment contains a detailed description of a single audio event in the song. It includes harmonic data (i.e. the pitch content), timbral data (the texture of the sound) and a loudness profile. Using this info we can create a Beat Distance Function (BDF) that will return a value that represents the relative distance between any two beats in the audio space. Beats that are close together in this space sound very similar, beats that are far apart sound very different. The BDF works by calculating the average distance between overlapping segments of the two beats where the distance between any two segments is a weighted combination of the euclidean distance between the pitch, timbral, loudness, duration and confidence vectors. The weights control which part of the sound takes more precedence in determining beat distance. For instance we can give more weight to the harmonic content of a beat, or the timbral quality of the beat. There’s no hard science for selecting the weights, I just picked some weights to start with and tweaked them a few times based on how well it worked. I started with the same weights that I used when creating the Infinite Jukebox (which also relies on beat similarity), but ultimately gave more weight to the harmonic component since good harmony is so important to The Autocanonizer.
(1B) Build simultaneous audio streams – building the canon
The next challenge, and perhaps biggest challenge of the whole app, is to build the canon – that is – given the Beat Distance Function, create two audio streams, one beat at a time, that sound good when played simultaneously. The first stream is easy, we’ll just play the beats in normal beat order. It’s the second stream, the canon stream that we have to worry about. The challenge: put the beats in the canon stream in an order such that (1) the beats are in a different order than the main stream, and (2) they sound good when played with the main stream.
The first thing we can try is to make each beat in the canon stream be the most similar sounding beat to the corresponding beat in the main stream. If we do that we end up with something that looks like this:
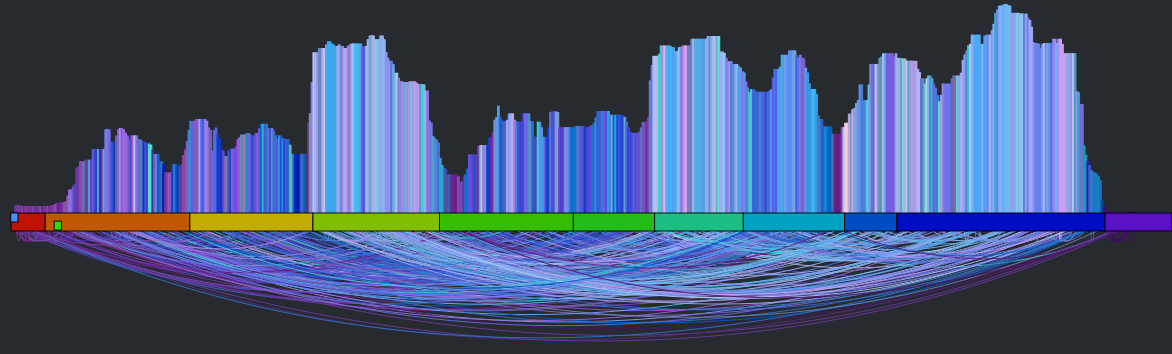
It’s a rat’s nest of connections, very little structure is evident. You can listen to what it sounds like by clicking here: Experimental Rat’s Nest version of Someone Like You (autocanonized). It’s worth a listen to get a sense of where we start from. So why does this bounce all over the place like this? There are lots of reasons: First, there’s lots of repetition in music – so if I’m in the first chorus, the most similar beat may be in the second or third chorus – both may sound very similar and it is practically a roll of the dice which one will win leading to much bouncing between the two choruses. Second – since we have to find a similar beat for every beat, even beats that have no near neighbors have to be forced into the graph which turns it into spaghetti. Finally, the underlying beat distance function relies on weights that are hard to generalize for all songs leading to more noise. The bottom line is that this simple approach leads to a chaotic and mostly non-musical canon with head-jarring transitions on the canon channel. We need to do better.
There are glimmers of musicality in this version though. Every once in a while, the canon channel will remaining on a single sequential set of beats for a little while. When this happens, it sounds much more musical. If we can make this happen more often, then we may end up with a better sounding canon. The challenge then is to find a way to identify long consecutive strands of beats that fit well with the main stream. One approach is to break down the main stream into a set of musically coherent phrases and align each of those phrases with a similar sounding coherent phrase. This will help us avoid the many head-jarring transitions that occur in the previous rat’s nest example. But how do we break a song down into coherent phrases? Luckily, it is already done for us. The Echo Nest analysis includes a breakdown of a song into sections – high level musically coherent phrases in the song – exactly what we are looking for. We can use the sections to drive the mapping. Note that breaking a song down into sections is still an open research problem – there’s no perfect algorithm for it yet, but The Echo Nest algorithm is a state-of-the-art algorithm that is probably as good as it gets. Luckily, for this task, we don’t need a perfect algorithm. In the above visualization you can see the sections. Here’s a blown up version – each of the horizontal colored rectangles represents one section:
![]()
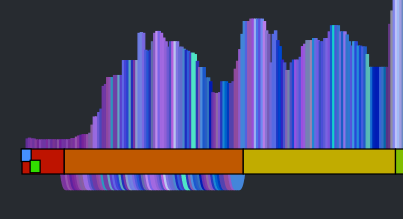
You can see that this song has 11 sections. Our goal then is to get a sequence of beats for the canon stream that aligns well with the beats of each section. To make things at little easier to see, lets focus in on a single section. The following visualization shows the similar beat graph for a single section (section 3) in the song:

You can see bundles of edges leaving section 3 bound for section 5 and 6. We could use these bundles to find most similar sections and simply overlap these sections. However, given that sections are rarely the same length nor are they likely to be aligned to similar sounding musical events, it is unlikely that this would give a good listening experience. However, we can still use this bundling to our advantage. Remember, our goal is to find a good coherent sequence of beats for the canon stream. We can make a simplifying rule that we will select a single sequence of beats for the canon stream to align with each section. The challenge, then, is to simply pick the best sequence for each section. We can use these edge bundles to help us do this. For each beat in the main stream section we calculate the distance to its most similar sounding beat. We aggregate these counts and find the most commonly occurring distance. For example, there are 64 beats in Section 3. The most common occurring jump distance to a sibling beat is 184 beats away. There are ten beats in the section with a similar beat at this distance. We then use this most common distance of 184 to generate the canon stream for the entire section. For each beat of this section in the main stream, we add a beat in the canon stream that is 184 beats away from the main stream beat. Thus for each main stream section we find the most similar matching stream of beats for the canon stream. This visualizing shows the corresponding canon beat for each beat in the main stream.

This has a number of good properties. First, the segments don’t need to be perfectly aligned with each other. Note, in the above visualization that the similar beats to section 3 span across section 5 and 6. If there are two separate chorus segments that should overlap, it is no problem if they don’t start at the exactly the same point in the chorus. The inter-beat distance will sort it all out. Second, we get good behavior even for sections that have no strong complimentary section. For instance, the second section is mostly self-similar, so this approach aligns the section with a copy of itself offset by a few beats leading to a very nice call and answer.
That’s the core mechanism of the autocanonizer – for each section in the song, find the most commonly occurring distance to a sibling beat, and then generate the canon stream by assembling beats using that most commonly occurring distance. The algorithm is not perfect. It fails badly on some songs, but for many songs it generates a really good cannon affect. The gallery has 20 or so of my favorites.
(2) Play the streams back simultaneously
When I first released my hack, to actually render the two streams as audio, I played each beat of the two streams simultaneously using the web audio API. This was the easiest thing to do, but for many songs this results in some very noticeable audio artifacts at the beat boundaries. Any time there’s an interruption in the audio stream there’s likely to be a click or a pop. For this to be a viable hack that I want to show people I really needed to get rid of those artifacts. To do this I take advantage of the fact that for the most part we are playing longer sequences of continuous beats. So instead of playing a single beat at a time, I queue up the remaining beats in the song, as a single queued buffer. When it is time to play the next beat, I check to see if is the same that would naturally play if I let the currently playing queue continue. If it is I ‘let it ride’ so to speak. The next beat plays seamlessly without any audio artifacts. I can do this for both the main stream and the canon stream. This virtually elimianates all the pops and clicks. However, there’s a complicating factor. A song can vary in tempo throughout, so the canon stream and the main stream can easily get out of sync. To remedy this, at every beat we calculate the accumulated timing error between the two streams. If this error exceeds a certain threshold (currently 50ms), the canon stream is resync’d starting from the current beat. Thus, we can keep both streams in sync with each other while minimizing the need to explicitly queue beats that results in the audio artifacts. The result is an audio stream that is nearly click free.
(3) Supply a visualization that gives the listener an idea of how the app works
I’ve found with many of these remixing apps, giving the listener a visualization that helps them understand what is happening under the hood is a key part of the hack. The first visualization that accompanied my hack was rather lame:
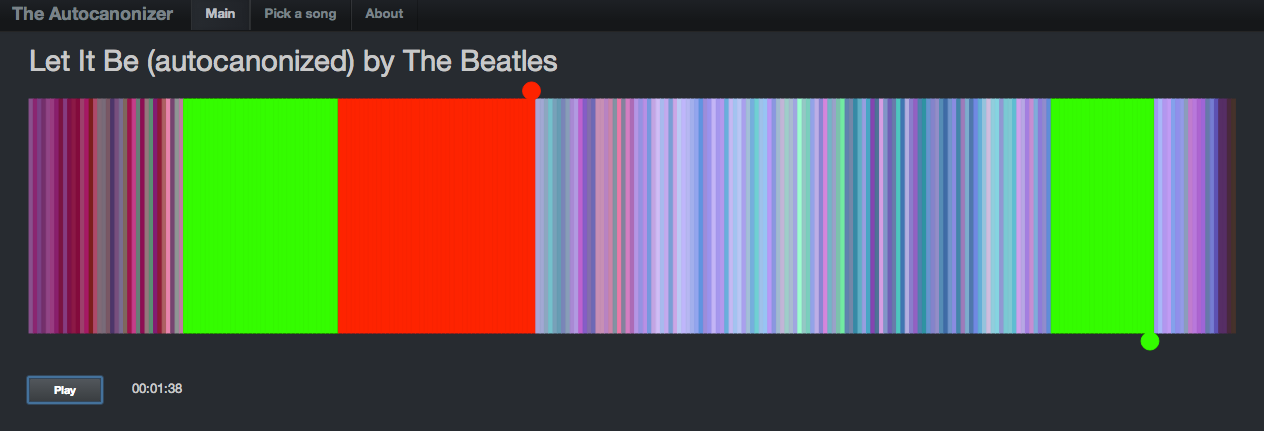
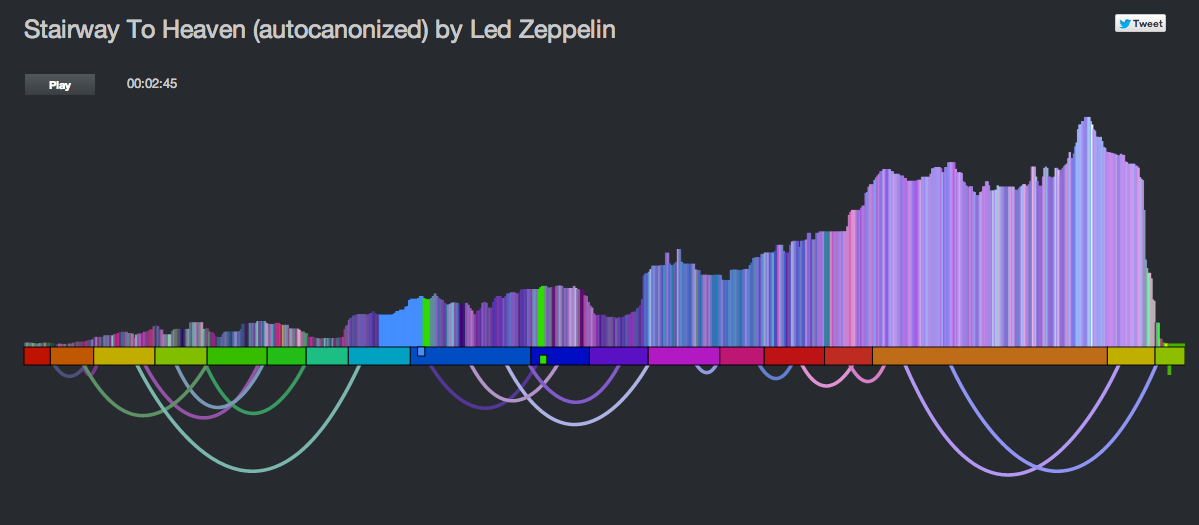
It showed the beats lined up in a row, colored by the timbral data. The two playback streams were represented by two ‘tape heads’ – the red tape head playing the main stream and the green head showing the canon stream. You could click on beats to play different parts of the song, but it didn’t really give you an idea what was going on under the hood. In the few days since the hackathon, I’ve spent a few hours upgrading the visualization to be something better. I did four things: Reveal more about the song structure, show the song sections, show, the canon graph and animate the transitions.
Reveal more about the song
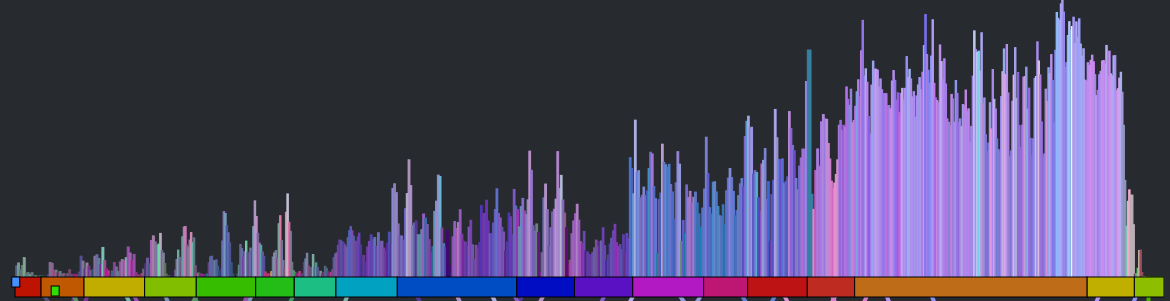
The colored bars don’t really tell you too much about the song. With a good song visualization you should be able to tell the difference between two songs that you know just by looking at the visualization. In addition to the timbral coloring, showing the loudness at each beat should reveal some of the song structure. Here’s a plot that shows the beat-by-beat loudness for the song stairway to heaven.
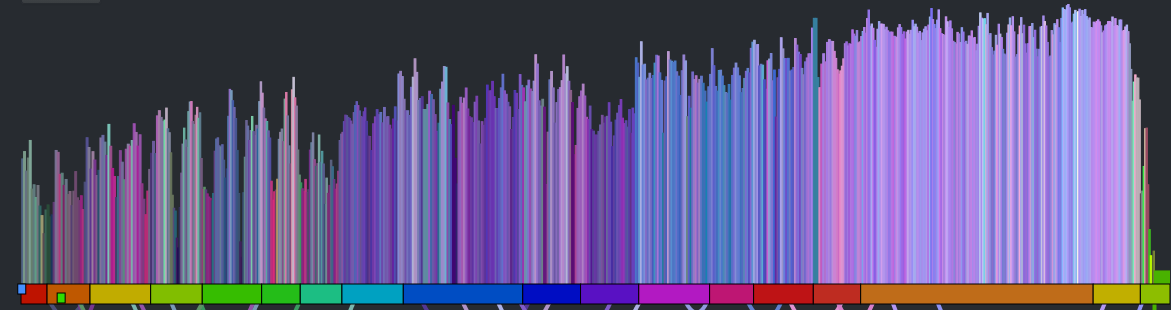
You can see the steady build in volume over the course of the song. But it is still less than an ideal plot. First of all, one would expect the build for a song like Stairway to Heaven to be more dramatic than this slight incline shows. This is because the loudness scale is a logarithmic scale. We can get back some of the dynamic range by converting to a linear scale like so:
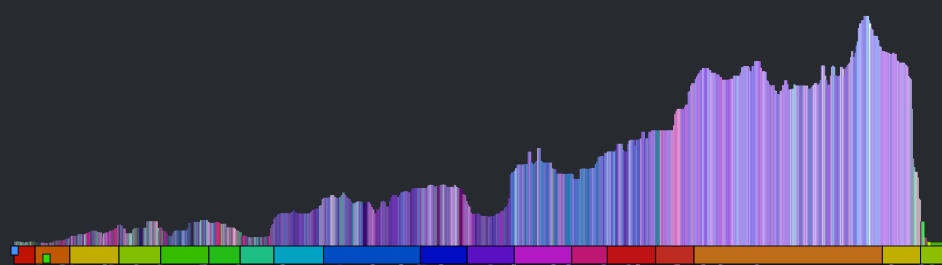
This is much better, but the noise still dominates the plot. We can smooth out the noise by taking a windowed average of the loudness for each beat. Unfortunately, that also softens the sharp edges so that short events, like ‘the drop’ could get lost. We want to be able to preserve the edges for significant edges while still eliminating much of the noise. A good way to do this is to use a median filter instead of a mean filter. When we apply such a filter we get a plot that looks like this:
The noise is gone, but we still have all the nice sharp edges. Now there’s enough info to help us distinguish between two well known songs. See if you can tell which of the following songs is ‘A day in the life’ by The Beatles and which one is ‘Hey Jude’ by The Beatles.
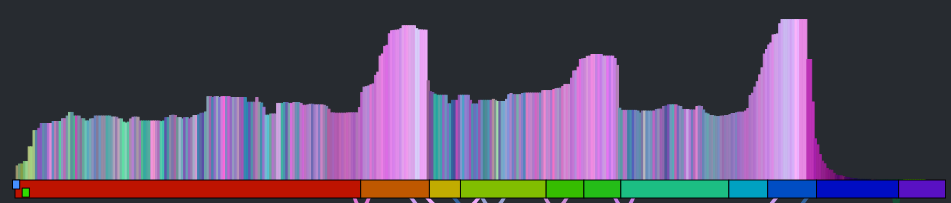
Which song is it? Hey Jude or A day in the Life?
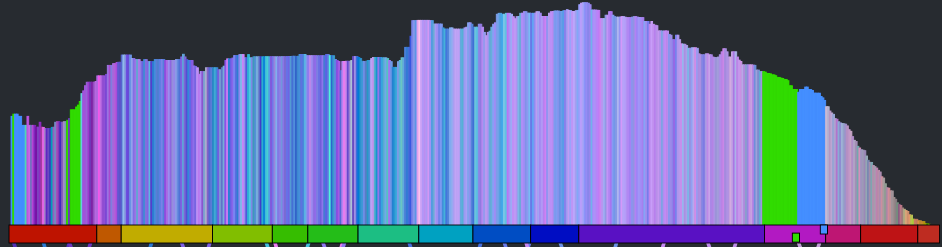
Which song is it? Hey Jude or A day in the Life?
Show the song sections
As part of the visualization upgrades I wanted to show the song sections to help show where the canon phrase boundaries are. To do this I created a the simple set of colored blocks along the baseline. Each one aligns with a section. The colors are assigned randomly.
Show the canon graph and animate the transitions.
To help the listener understand how the canon is structured, I show the canon transitions as arcs along the bottom of the graph. When the song is playing, the green cursor, representing the canon stream animates along the graph giving the listener a dynamic view of what is going on. The animations were fun to do. They weren’t built into Raphael, instead I got to do them manually. I’m pretty pleased with how they came out.

All in all I think the visualization is pretty neat now compared to where it was after the hack. It is colorful and eye catching. It tells you quite a bit about the structure and make up of a song (including detailed loudness, timbral and section info). It shows how the song will be represented as a canon, and when the song is playing it animates to show you exactly what parts of the song are being played against each other. You can interact with the vizualization by clicking on it to listen to any particular part of the canon.
Wrapping up – this was a fun hack and the results are pretty unique. I don’t know of any other auto-canonizing apps out there. It was pretty fun to demo that hack at the SXSW Music Hack Championships too. People really seemed to like it and even applauded spontaneously in the middle of my demo. The updates I’ve made since then – such as fixing the audio glitches and giving the visualization a face lift make it ready for the world to come and visit. Now I just need to wait for them to come.
Learn about a new genre every day
Posted by Paul in code, genre, playlist, The Echo Nest on January 16, 2014
The Echo Nest knows about 800 genres of music (and that number is growing all the time). Among those 800 genres are ones that you already know about, like ‘jazz’,’rock’ and ‘classical’. But there are also hundreds of genres that you’ve probably never heard of. Genres like Filthstep, Dangdut or Skweee. Perhaps the best way to explore the genre space is via Every Noise at Once (built by Echo Nest genre-master Glenn McDonald). Every Noise At Once shows you the whole genre space, allowing you to explore the rich and varied universe of music. However, Every Noise at Once can be like drinking Champagne from a firehose – there’s just too much to take in all at once (it is, after all, every noise – at once). If you’d like to take a slower and more measured approach to learning about new music genres, you may be interested in Genre-A-Day.
Genre-A-Day is a web app that presents a new genre every day. Genre-A-Day tells you about the genre, shows you some representative artists for the genre, lets you explore similar genres, and lets you listen to music in the genre.
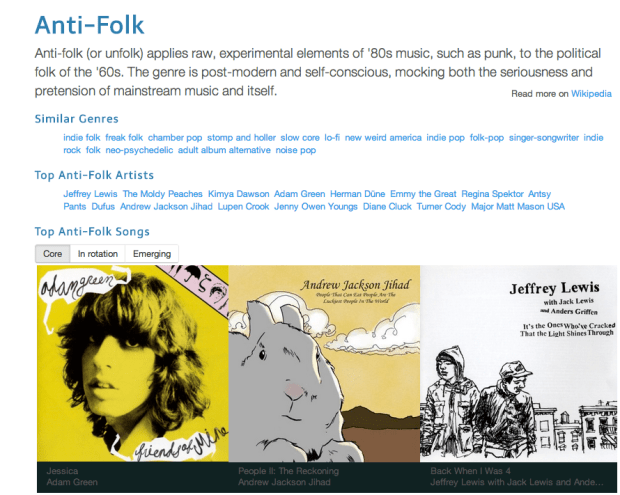
If you spend a few minutes every day reading about and listening to a new genre, after a few months you’ll be a much more well-rounded music listener, and after a few years your knowledge of genres will rival most musicologists’.
An easy way to make Genre-A-Day part of your daily routine is to follow @GenreADay on twitter. GenreADay will post a single tweet, once a day like so:
Under the hood – Genre-A-Day was built using the just released genre methods of The Echo Nest API. These methods allow you to get detailed info on the set of genres, the top artists for the genres, similar genres and so on. It also uses the super nifty genre presets in the playlist API that allow you to craft the genre-radio listener for someone who is new to the genre (core), for someone who is a long time listener of the genre (in rotation), or for someone looking for the newest music in that genre (emerging). The source code for Genre-A-Day is on github.
