Archive for category events
More on “Where’s the Drama?”
Posted by Paul in code, events, Music, music hack day, Spotify, The Echo Nest on September 8, 2014
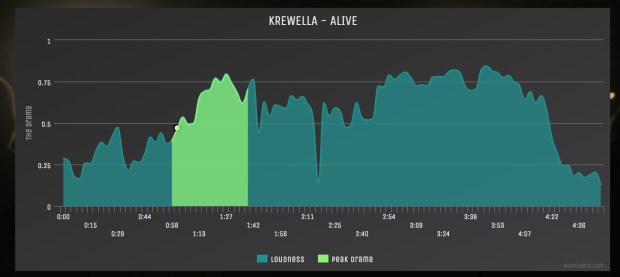
My Music Hack Day Berlin hack was “Where’s the Drama?” – a web app that automatically identifies the most dramatic moment in any song and plays it for you. I’ve been having lots of fun playing with it … and even though (or perhaps because) I know how it works, I’m often surprised at how well it does at finding the most dramatic moments. Here are some examples:
- When will the Bass Drop – Lonely Island
- Stairway to Heaven – Led Zeppelin
- Doomsday – Nero
- November Rain – Guns N Roses
How does it work? The app grabs the detailed audio analysis for the song from The Echo Nest. This includes a detailed loudness map of the song. This is the data I use to find the drama. To do so, I look for the part of the song with the largest rise in volume over the course of a 30 second window (longer songs can have a bit of a longer dramatic window). I give extra weight to crescendos that culminate in louder peaks (so if there are two crescendos that are 20dB in range but one ends at 5dB louder, it will win). Once I identify the most dynamic part of a song, I pad it a bit (so we get to hear a bit of the drop after the build).
The rest is just UI – the song gets plotted as a heavily filtered loudness curve with the dramatic passage highlighted. I plot things with Highcharts, which is a pretty nifty javascript plotting and charting library. I recommend.
Playing the music – I wanted to use Spotify to play the music, which was a bit problematic since there currently isn’t a way to play full streams with the Spotify Web API, so I did a couple of hacky hacks that got me pretty far. First of all, I discovered that you can add a time offset to a Spotify URI like so:
When this URI is opened in Spotify (even when opened via a browser), Spotify will start to play the song a the 1:05 time offset.
I still needed to be able to stop playing the track – and there’s no way to do that directly – so instead, I just open the URI:
which happens to be the URI for John Cage’s 4’33. In other words, to stop playing one track, I just start playing another (that happens to be silent). The awesome side effect of this is that I’ll be slowly turning anyone who uses “Where’s the Drama?” into experimental music listeners as the Spotify recommendation system responds to all of those John Cage ‘plays’. This should win some sort of ‘hackiest hack of the year’ award.
It was a fun hack to make, and great fun to demo. And now that I have the app, I am no longer wasting time listening to song intros and outros, I can just get to the bit of the song that matters the most.
Outside Lands Recommendations
Posted by Paul in code, events, hacking, recommendation, Spotify, The Echo Nest on July 27, 2014
I am at Outside Hacks this weekend – A hackathon associated with the Outside Lands music festival. For this hack I thought it would be fun to try out the brand new Your Music Library endpoints in the Spotify Web API. These endpoints let you inspect and manipulate the tracks that a user has saved to their music. Since the hackathon is all about building apps for a music festival, it seems natural to create a web app that gives you festival artist recommendations based upon your Spotify saved tracks. The result is the Outside Lands Recommender:

The Recommender works by pulling in all the saved tracks from your Spotify ‘Your Music’ collection, aggregating the artists and then using the Echo Nest Artist Similar API to find festival artists that match or are similar to those artists. The Spotify API is then used to retrieve artist images and audio samples for the recommendations where they are presented in all of their bootstrap glory.
This was a pretty straight forward app, which was good since I only had about half the normal hacking time for a weekend hackathon. I spent the other half of the time building a festival dataset for hackers to use (as well as answering lots of questions about both the Spotify and Echo Nest APIs).
It has been a very fun hackathon. It is extremely well organized, the Weebly location is fantastic, and the quality of hackers is very high. I’ve already seen some fantastic looking hacks and we are still a few hours from demo time. Plus, this happened.

Two more victims
1st Web Audio Conference
This January IRCAM and Mozilla will be hosting the 1st Web Audio Conference in Paris France. From the conference page:
The WAC is the first international conference on web audio technologies and applications.
The conference welcomes web R&D developers, audio processing scientists, application designers and people involved in web standards.
The conference addresses research, development, design, and standards concerned with emerging audio-related web technologies such as Web Audio API, Web RTC, Web Sockets, and Javascript.
Contributions to the first edition of WAC are encouraged in, but not limited to, the following topics:
- Innovative audio and music based web applications (with social and user experience aspects)
- Client-side audio processing (real-time or non real-time)
- Audio data and metadata formats and network delivery
- Server-side audio processing and client access
- Client-side audio engine and rendering
- Frameworks for audio manipulation
- Web Audio API design and implementation
- Client-side audio visualization
- Multimedia integration
- Web standards and use of standards within audio based web projects
- Hardware, tangible interface and use of Web Audio API
This is the first Call For Papers that I’ve seen that, in addition to a paper and poster track, also has a Gig submission track. Yes, you can propose a 20 minute gig. Accepted gigs will be presented in the conference concert. I’m thinking of a combined Infinite Jukebox + Ellie Goulding visualization – 20 minutes of flying cubes will show ’em.
The submission deadline is October 10. Time to dust off my Latex skills.
How the Autocanonizer works
Posted by Paul in code, data, events, fun, genre, hacking, music hack day, The Echo Nest on March 18, 2014
Last week at the SXSW Music Hack Championship hackathon I built The Autocanonizer. An app that tries to turn any song into a canon by playing it against a copy of itself. In this post, I explain how it works.
At the core of The Autocanonizer are three functions – (1) Build simultaneous audio streams for the two voices of the canon (2) Play them back simultaneously, (3) Supply a visualization that gives the listener an idea of what is happening under the hood. Let’s look at each of these 3 functions:
(1A) Build simultaneous audio streams – finding similar sounding beats
The goal of the Autocanonizer is to fold a song in on itself in such a way that the result still sounds musical. To do this, we use The Echo Nest analyzer and the jremix library to do much of the heavy lifting. First we use the analyzer to break the song down into beats. Each beat is associated with a timestamp, a duration, a confidence and a set of overlapping audio segments. An audio segment contains a detailed description of a single audio event in the song. It includes harmonic data (i.e. the pitch content), timbral data (the texture of the sound) and a loudness profile. Using this info we can create a Beat Distance Function (BDF) that will return a value that represents the relative distance between any two beats in the audio space. Beats that are close together in this space sound very similar, beats that are far apart sound very different. The BDF works by calculating the average distance between overlapping segments of the two beats where the distance between any two segments is a weighted combination of the euclidean distance between the pitch, timbral, loudness, duration and confidence vectors. The weights control which part of the sound takes more precedence in determining beat distance. For instance we can give more weight to the harmonic content of a beat, or the timbral quality of the beat. There’s no hard science for selecting the weights, I just picked some weights to start with and tweaked them a few times based on how well it worked. I started with the same weights that I used when creating the Infinite Jukebox (which also relies on beat similarity), but ultimately gave more weight to the harmonic component since good harmony is so important to The Autocanonizer.
(1B) Build simultaneous audio streams – building the canon
The next challenge, and perhaps biggest challenge of the whole app, is to build the canon – that is – given the Beat Distance Function, create two audio streams, one beat at a time, that sound good when played simultaneously. The first stream is easy, we’ll just play the beats in normal beat order. It’s the second stream, the canon stream that we have to worry about. The challenge: put the beats in the canon stream in an order such that (1) the beats are in a different order than the main stream, and (2) they sound good when played with the main stream.
The first thing we can try is to make each beat in the canon stream be the most similar sounding beat to the corresponding beat in the main stream. If we do that we end up with something that looks like this:
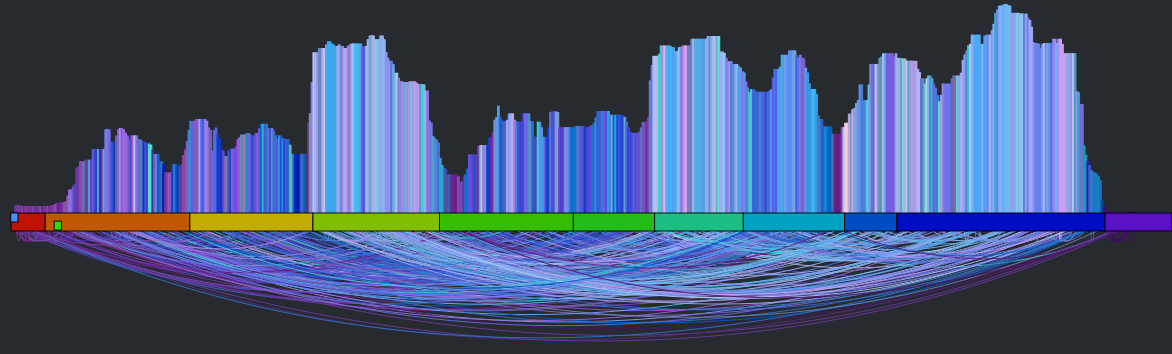
It’s a rat’s nest of connections, very little structure is evident. You can listen to what it sounds like by clicking here: Experimental Rat’s Nest version of Someone Like You (autocanonized). It’s worth a listen to get a sense of where we start from. So why does this bounce all over the place like this? There are lots of reasons: First, there’s lots of repetition in music – so if I’m in the first chorus, the most similar beat may be in the second or third chorus – both may sound very similar and it is practically a roll of the dice which one will win leading to much bouncing between the two choruses. Second – since we have to find a similar beat for every beat, even beats that have no near neighbors have to be forced into the graph which turns it into spaghetti. Finally, the underlying beat distance function relies on weights that are hard to generalize for all songs leading to more noise. The bottom line is that this simple approach leads to a chaotic and mostly non-musical canon with head-jarring transitions on the canon channel. We need to do better.
There are glimmers of musicality in this version though. Every once in a while, the canon channel will remaining on a single sequential set of beats for a little while. When this happens, it sounds much more musical. If we can make this happen more often, then we may end up with a better sounding canon. The challenge then is to find a way to identify long consecutive strands of beats that fit well with the main stream. One approach is to break down the main stream into a set of musically coherent phrases and align each of those phrases with a similar sounding coherent phrase. This will help us avoid the many head-jarring transitions that occur in the previous rat’s nest example. But how do we break a song down into coherent phrases? Luckily, it is already done for us. The Echo Nest analysis includes a breakdown of a song into sections – high level musically coherent phrases in the song – exactly what we are looking for. We can use the sections to drive the mapping. Note that breaking a song down into sections is still an open research problem – there’s no perfect algorithm for it yet, but The Echo Nest algorithm is a state-of-the-art algorithm that is probably as good as it gets. Luckily, for this task, we don’t need a perfect algorithm. In the above visualization you can see the sections. Here’s a blown up version – each of the horizontal colored rectangles represents one section:
![]()
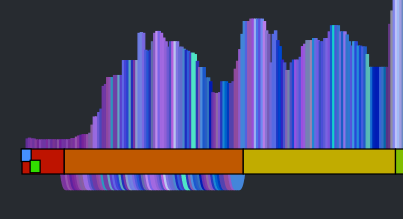
You can see that this song has 11 sections. Our goal then is to get a sequence of beats for the canon stream that aligns well with the beats of each section. To make things at little easier to see, lets focus in on a single section. The following visualization shows the similar beat graph for a single section (section 3) in the song:

You can see bundles of edges leaving section 3 bound for section 5 and 6. We could use these bundles to find most similar sections and simply overlap these sections. However, given that sections are rarely the same length nor are they likely to be aligned to similar sounding musical events, it is unlikely that this would give a good listening experience. However, we can still use this bundling to our advantage. Remember, our goal is to find a good coherent sequence of beats for the canon stream. We can make a simplifying rule that we will select a single sequence of beats for the canon stream to align with each section. The challenge, then, is to simply pick the best sequence for each section. We can use these edge bundles to help us do this. For each beat in the main stream section we calculate the distance to its most similar sounding beat. We aggregate these counts and find the most commonly occurring distance. For example, there are 64 beats in Section 3. The most common occurring jump distance to a sibling beat is 184 beats away. There are ten beats in the section with a similar beat at this distance. We then use this most common distance of 184 to generate the canon stream for the entire section. For each beat of this section in the main stream, we add a beat in the canon stream that is 184 beats away from the main stream beat. Thus for each main stream section we find the most similar matching stream of beats for the canon stream. This visualizing shows the corresponding canon beat for each beat in the main stream.

This has a number of good properties. First, the segments don’t need to be perfectly aligned with each other. Note, in the above visualization that the similar beats to section 3 span across section 5 and 6. If there are two separate chorus segments that should overlap, it is no problem if they don’t start at the exactly the same point in the chorus. The inter-beat distance will sort it all out. Second, we get good behavior even for sections that have no strong complimentary section. For instance, the second section is mostly self-similar, so this approach aligns the section with a copy of itself offset by a few beats leading to a very nice call and answer.
That’s the core mechanism of the autocanonizer – for each section in the song, find the most commonly occurring distance to a sibling beat, and then generate the canon stream by assembling beats using that most commonly occurring distance. The algorithm is not perfect. It fails badly on some songs, but for many songs it generates a really good cannon affect. The gallery has 20 or so of my favorites.
(2) Play the streams back simultaneously
When I first released my hack, to actually render the two streams as audio, I played each beat of the two streams simultaneously using the web audio API. This was the easiest thing to do, but for many songs this results in some very noticeable audio artifacts at the beat boundaries. Any time there’s an interruption in the audio stream there’s likely to be a click or a pop. For this to be a viable hack that I want to show people I really needed to get rid of those artifacts. To do this I take advantage of the fact that for the most part we are playing longer sequences of continuous beats. So instead of playing a single beat at a time, I queue up the remaining beats in the song, as a single queued buffer. When it is time to play the next beat, I check to see if is the same that would naturally play if I let the currently playing queue continue. If it is I ‘let it ride’ so to speak. The next beat plays seamlessly without any audio artifacts. I can do this for both the main stream and the canon stream. This virtually elimianates all the pops and clicks. However, there’s a complicating factor. A song can vary in tempo throughout, so the canon stream and the main stream can easily get out of sync. To remedy this, at every beat we calculate the accumulated timing error between the two streams. If this error exceeds a certain threshold (currently 50ms), the canon stream is resync’d starting from the current beat. Thus, we can keep both streams in sync with each other while minimizing the need to explicitly queue beats that results in the audio artifacts. The result is an audio stream that is nearly click free.
(3) Supply a visualization that gives the listener an idea of how the app works
I’ve found with many of these remixing apps, giving the listener a visualization that helps them understand what is happening under the hood is a key part of the hack. The first visualization that accompanied my hack was rather lame:
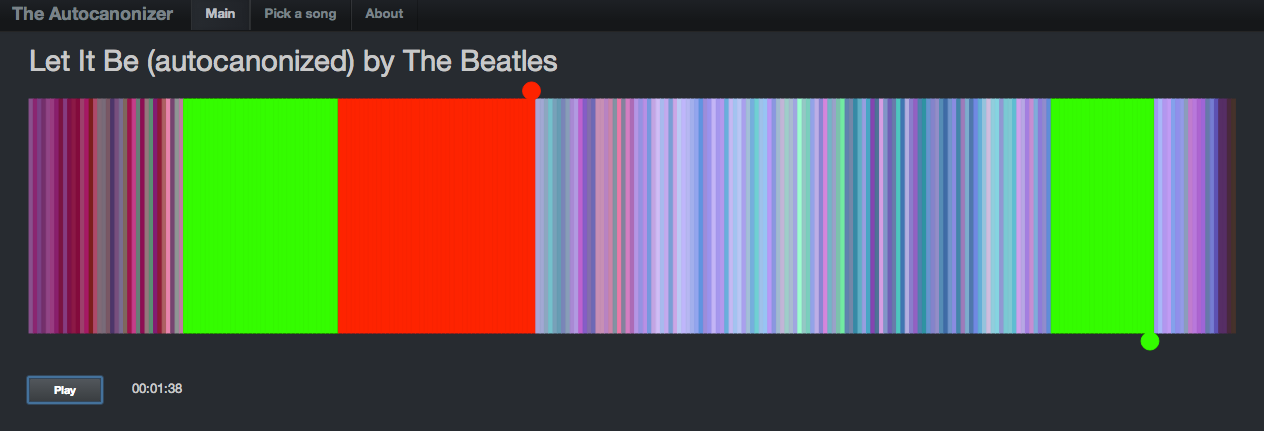
It showed the beats lined up in a row, colored by the timbral data. The two playback streams were represented by two ‘tape heads’ – the red tape head playing the main stream and the green head showing the canon stream. You could click on beats to play different parts of the song, but it didn’t really give you an idea what was going on under the hood. In the few days since the hackathon, I’ve spent a few hours upgrading the visualization to be something better. I did four things: Reveal more about the song structure, show the song sections, show, the canon graph and animate the transitions.
Reveal more about the song
The colored bars don’t really tell you too much about the song. With a good song visualization you should be able to tell the difference between two songs that you know just by looking at the visualization. In addition to the timbral coloring, showing the loudness at each beat should reveal some of the song structure. Here’s a plot that shows the beat-by-beat loudness for the song stairway to heaven.
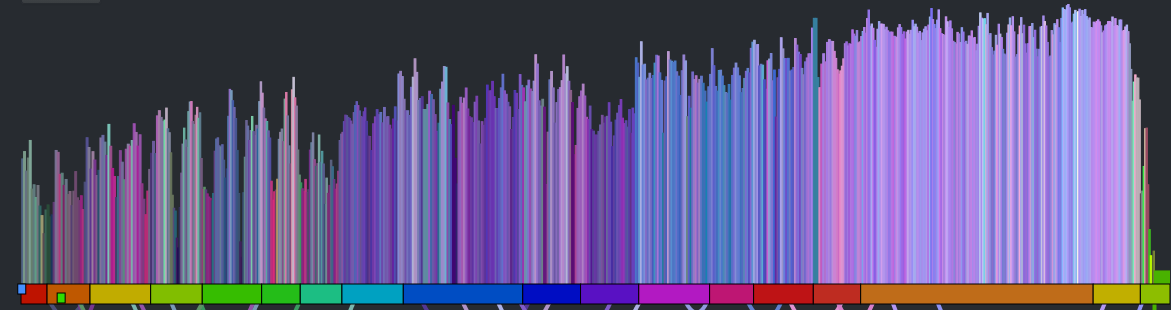
You can see the steady build in volume over the course of the song. But it is still less than an ideal plot. First of all, one would expect the build for a song like Stairway to Heaven to be more dramatic than this slight incline shows. This is because the loudness scale is a logarithmic scale. We can get back some of the dynamic range by converting to a linear scale like so:
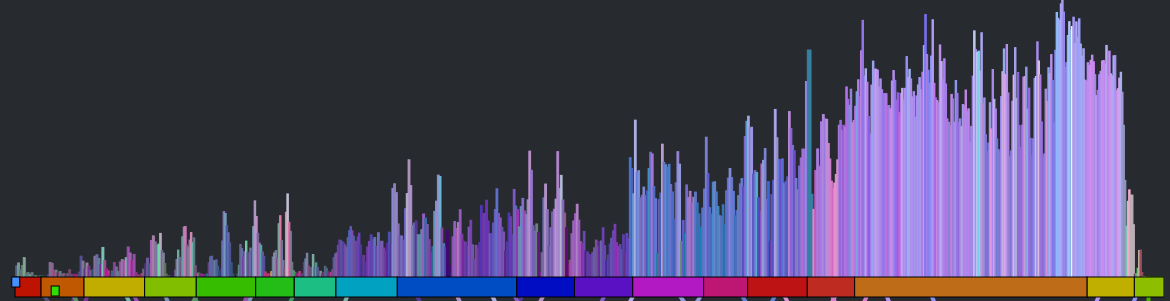
This is much better, but the noise still dominates the plot. We can smooth out the noise by taking a windowed average of the loudness for each beat. Unfortunately, that also softens the sharp edges so that short events, like ‘the drop’ could get lost. We want to be able to preserve the edges for significant edges while still eliminating much of the noise. A good way to do this is to use a median filter instead of a mean filter. When we apply such a filter we get a plot that looks like this:
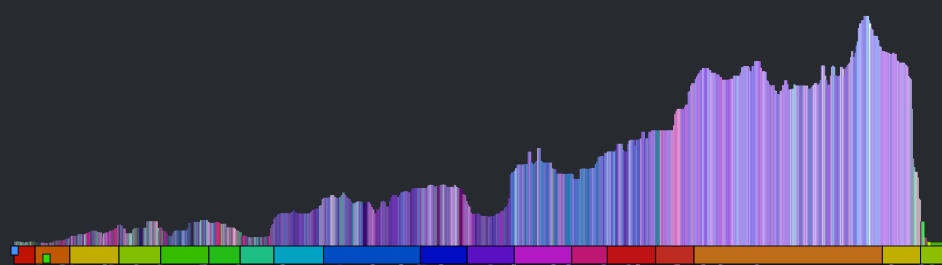
The noise is gone, but we still have all the nice sharp edges. Now there’s enough info to help us distinguish between two well known songs. See if you can tell which of the following songs is ‘A day in the life’ by The Beatles and which one is ‘Hey Jude’ by The Beatles.
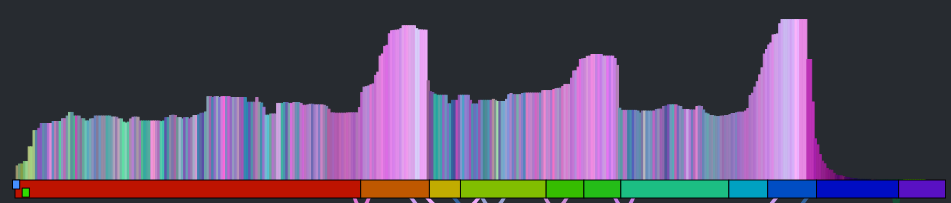
Which song is it? Hey Jude or A day in the Life?
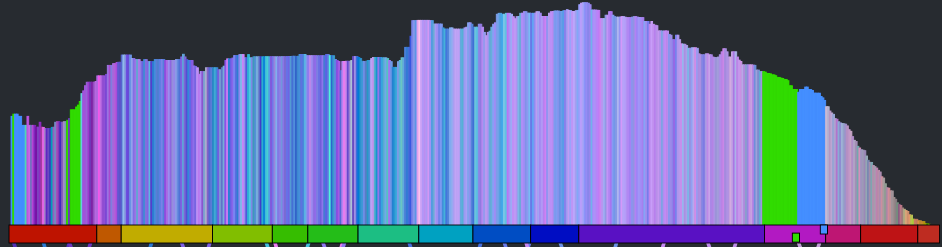
Which song is it? Hey Jude or A day in the Life?
Show the song sections
As part of the visualization upgrades I wanted to show the song sections to help show where the canon phrase boundaries are. To do this I created a the simple set of colored blocks along the baseline. Each one aligns with a section. The colors are assigned randomly.
Show the canon graph and animate the transitions.
To help the listener understand how the canon is structured, I show the canon transitions as arcs along the bottom of the graph. When the song is playing, the green cursor, representing the canon stream animates along the graph giving the listener a dynamic view of what is going on. The animations were fun to do. They weren’t built into Raphael, instead I got to do them manually. I’m pretty pleased with how they came out.

All in all I think the visualization is pretty neat now compared to where it was after the hack. It is colorful and eye catching. It tells you quite a bit about the structure and make up of a song (including detailed loudness, timbral and section info). It shows how the song will be represented as a canon, and when the song is playing it animates to show you exactly what parts of the song are being played against each other. You can interact with the vizualization by clicking on it to listen to any particular part of the canon.
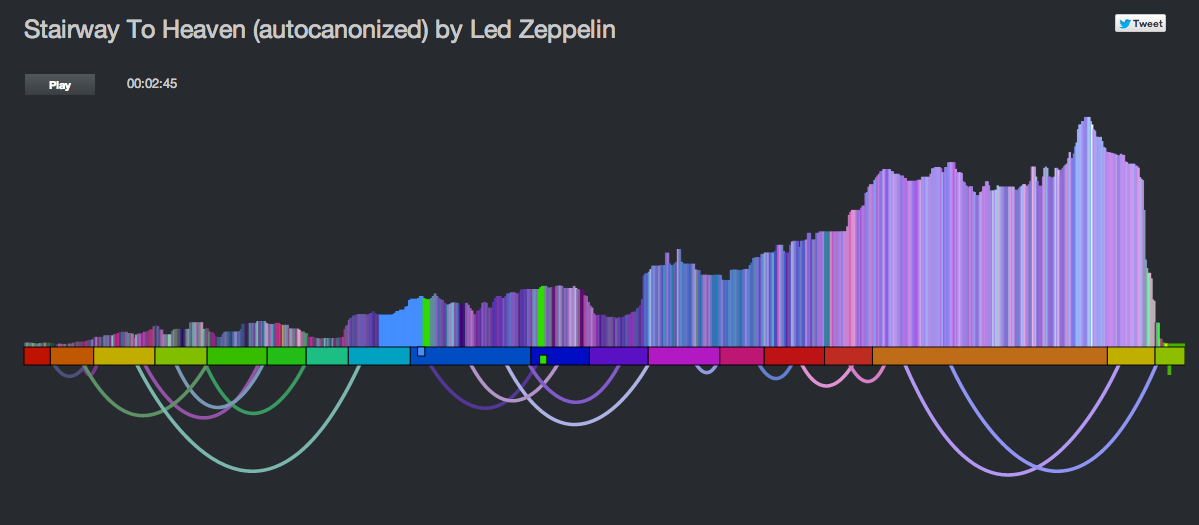
Wrapping up – this was a fun hack and the results are pretty unique. I don’t know of any other auto-canonizing apps out there. It was pretty fun to demo that hack at the SXSW Music Hack Championships too. People really seemed to like it and even applauded spontaneously in the middle of my demo. The updates I’ve made since then – such as fixing the audio glitches and giving the visualization a face lift make it ready for the world to come and visit. Now I just need to wait for them to come.
The Autocanonizer
Posted by Paul in code, events, hacking, The Echo Nest on March 13, 2014
I’ve spent the last 24 hours at the SXSW Music Hackathon championship. For my hack I’ve built something called The Autocanonizer. It takes any song and tries to make a canon out of it. A canon is a song that can be played against a copy of itself. The Autocanonizer does this by looking at the detailed audio in the song (via The Echo Nest analysis), and looks for parts of the song that might overlap well. It builds a map of all these parts and when it plays the song it plays the main audio, while overlapping it with the second audio stream. It doesn’t always work, but when it does, the results can be quite fun and sometimes quite pleasing.
To go along with the playback I created a visualization that shows the song and the two virtual tape heads that are playing the song. You can click on the visualization to hear particular bits.
There are some audio artifacts on a few songs still. I know how to fix it, but it requires some subtle math (subtraction) that I’m sure I’ll mess up right before the hackathon demo if I attempt it now, so it will have to wait for another day. Also, there’s a Firefox issue that I will fix in the coming days. Or you can go and fix all this yourself because the code is on github.
The Perfect Music Hack Day – London 2013
Posted by Paul in events, music hack day on December 10, 2013
This weekend, Music Hack Day returned to the city where it all began. On Saturday morning, nearly 200 hackers arrived with the hottest hackathon tickets at the Shoreditch Works Village Hall, in Hoxton Square to spend the weekend exercising their passion for music and technology. After 24 hours of hacking, over 50 hacks were built – hacks that let you explore, discover, arrange, create and play with music.

Augdrum – Hacked drum for use in ‘expressive’ performance
I’ve been to many Music Hack Days, and I must say this was a special one. It had all the magical ingredients to make this the perfect event. First, the Shoreditch Works Village Hall was the ideal hacking venue.

Getting ready to hack at the Shoreditch Works Village Hall
It is located in the heart of London’s exploding tech community, surrounded by pubs and restaurants (in my five minute walk from the hotel to the Village Hall, I walked past a dozen pubs). The Village Hall had perfect power and ample bandwidth for 200 data-starved hackers. The hackathon was sold out and everyone showed up, so we were all tightly packed into the hall – adding to the crazy energy. There’s a coffee shop connected to the hall where baristas were preparing coffee for the hackers long into the night.

Food was not your standard hacker pizza – it was “modern British slow cooking” provided by the Bow Street Kitchen. It really added to the London vibe.

Finally, Thomas Bonte of MuseScore was in attendance – Thomas is the official photographer of Music Hack Day. He’s been taking pictures of MHD since the very first one. He takes great pictures and makes them all available on Flickr via Creative Commons. Check out his full set of the event on Flickr. He took nearly all the photos in this blog post except for this one:

Thomas Bonte at work
Since the event was sure to sell out (everyone wants to go to a London Music Hack day), only the most motivated hackers were able to get tickets. Motivated hackers are the best kind of hackers.

Full house – hacker style
These are the folks that arrive early, stay late, work hard and finish their hacks on time – leading to a very high level of hacks being built.

Full house for hackers at Music Hack Day
The event kicked off with organizer Martyn Davies providing opening remarks, followed by API presentations by various companies. By 2PM hacking was in full swing.

Martyn Davies kicking things off
24 hours later, 51 hacks had been completed and submitted to hacker league. The epic demo session started at 3PM and by 6PM all the demos had been completed and prizes were awarded. Unlike other hack days, all the prizes were pooled and distributed to the top hacks (determined by popular vote).

Andy Bennett’s rather complicated demo
A new and awesome twist to the demo session was provided by Becky Stewart’s hack. She created #mhdbingo – a set of custom bingo cards filled with common Music Hack Day tropes and memes. Each hacker received a unique bingo card to fill out during the demo session. Bingo wins were recorded by tweets with the #mhdbingo hashtag. Here’s a sample bingo card:
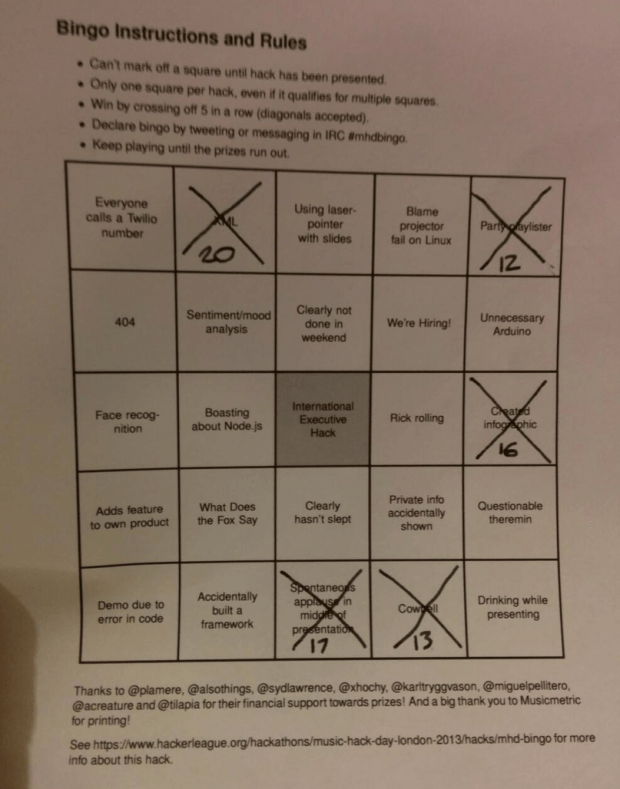
It’s the center square that’s the most interesting.
Becky’s hack not only provided a little humor for the demo session, but was a great tool to keep the attendees focused on the demo during the nearly 3 hour demo session. There was a point near the end of the demo session when seemingly dozens of folks were praying for a hack that showed ‘tracks on a map’ – and yes, their prayers were answered. Becky’s hack is on Github and she accepts pull requests so if you have suggestions for more MHD memes and tropes go ahead and add them and submit the pull requests. I’m sure #mhdbingo will become a fixture at future Music Hack days.

Watching the demos at Music Hack Day
Some of my favorite hacks of the weekend are:
Hipster Robot – A hipster robotic arm that stops you listening to any music it deems “too mainstream”
Didgidoo – An electronically augmented didgeridoo.

#mhdbingo – the aforementioned Bingo game celebrating all our favourite Music Hack Day tropes.

Becky combines Latex and Bingo to reshape Music Hack Day forever. Sitting behind her is someone else who, 10 years ago, reshaped music forever
notepad – Draw a piano on a paper pad, and start playing it!

These are your Burns – takes your favourite bit of audio at the moment (Your ‘jam’ if you will) and creates a beautiful collage of memes, informed by the lyrics of the song, and presents them in a familiar documentary style.

MidiModulator – This Python script will take a song and modulate the pitch with the melody of a chosen score (basically, another song). Think of it as FM, except instead of a frequency we take an entire Christmas carol.

playsongsto.me – a collaborative playlist tool with a difference – you have to convince your friends to keep adding tracks faster than you can listen to them or face the consequences! This hack was created by Ross Penman – the youngest hacker to demo a project. I really liked his unique double twist on the party playlister.

album pairs – a nearly ready for the iOs App Store is the Album Pairs app by Iain Mullan – its an album cover matching game – when you make the match the corresponding song is added to the playlist.
Block Surfer – Rhythms created from waves using a bit of 2D physics.
Chiptar – hacked a guitar to control an 8-bit C64-inspired synth engine. Using an accelerometer it’s also possible to control arpeggiation.

best new sounds at the hack
Attention Deficit Radio – This is my hack – Attention Deficit Radio creates a Pandora-like radio experience for music listeners with short attention spans.

The top popular crowd favorite was Lifesong. This hack was written by Ben Nunney entirely on an Amstrad 1512 – a mid-80s PC with 512k RAM and a 4Mhz processor. It’s based in Pascal with a BASIC wrapper around it.

Since this computer has no network, audio out, or video out, Ben had to resort to some unusual methods to demo his hack.

It was a really fun demo session. There were lots of unique hacks. See the full list on hacker league. Many APIs were used including Spotify, Deezer, Songkick, Last.fm, Twilio, SoundCloud, Discogs, MuseScore, MusicMetric and more. I was especially pleased to see that several dozen hacks use our Echo Nest API to make cool hacks.

Martyn doing his thing at Music Hack Day
Thanks to @martynd and everyone involved in organizing the Music Hack Day London. It really was the perfect Music Hack Day.
Thanks to Thomas Bonte for all the photos used in this post. Be sure to see the full set.
Attention Deficit Radio
Posted by Paul in code, data, events, fun, hacking, music hack day, The Echo Nest on December 8, 2013
This weekend, I’ve been in London, attending the London Music Hack Day. For this weekend’s hack, I was inspired by daughter’s music listening behavior – when she listens to music, she is good for the first verse or two and the chorus, but after that, she’s on to the next song. She probably has never heard a bridge. So for my daughter, and folks like her with short attention spans, I’ve built Attention Deficit Radio. ADR creates a Pandora-like radio station based upon a seed artist, but doesn’t bother you by playing whole songs. Instead, after about 30 seconds or so, it is on to the next song. The nifty bit is that ADR will try to beat-match and crossfade between the songs giving you a (hopefully) seamless listening experience as you fly through the playlist. Of course those with short attention spans need something to look at while listening, so ADR has lots of gauges that show the radio status – it shows the current beat, the status of the cross-fade, tempo and song loading status.
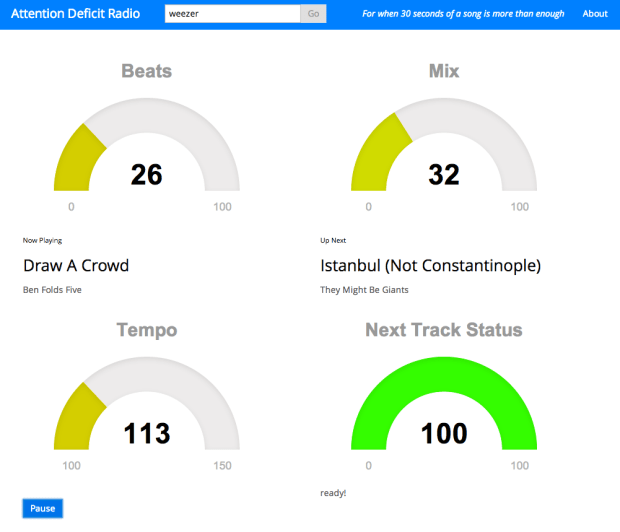
There may be a few rough edges, and the paint is not yet dry, but give Attention Deficit Radio a try if you have a short listening attention span.
No, I will not build your app for free pizza
Posted by Paul in events, music hack day on November 19, 2013

The Sydney Opera House hackathon is off to a bad start. The infamous institution is holding a hackathon next month. They are offering a prize of $4K AU (about $3, 750 US) along with ‘The glory of developing an app for Sydney Opera House which will be seen by millions of visitors every year’ for the best hack. The Register dove into the Terms & Conditions (warning, 2,000 words of legalize) and dug up all sorts of IP grabs. Bottom line, at the end of the hack the SOH can do just about anything it wants with what you built at the hackathon. To quote the Register:
“By entering this competition, every last line of code you cut becomes the property of the Sydney Opera House Trust.”
There’s also this little nugget in the T&C:
“By entering this Hackathon, you agree that use of information in our representatives’ unaided memories in the development or deployment of our products or services does not create liability for us”
One can just imagine how it this came about. Some biz guys (yeah, all evil comes from the biz guys) were sitting around thinking about how they could get their mobile app done for cheap. “Let’s do a hackathon! Toss a few bean bag chairs and power strips into a hotel conference room. Send in boxes of Pizza every 6 hours and out will pop dozens of apps to chose from. Even if none of the apps built are polished enough for release we will be able to mine all the best ideas from the most creative Australian techies and put them into our app when we finally hire that digital agency to build it.”
Unfortunately for the SOH, developers are too smart for that. They can do the math. To win a high profile hackathon with a goal of building a mobile app for millions of users, you probably need a team of four: the front-end programmer, the back-end programmer, the designer and the do-everything-else-including-the-presentation guy/gal (a.k.a The Face). At a modest $125 an hour per team member on the open market that team costs $500 per hour, so 24 hours of hacking is worth about $12,000. (That’s not even counting the pre-hack work that any team going to win will do – getting the code repository setup, the tools primed, the workflow established). The chance to win a $4K prize for $12K of work is just not worth it. And of course, the SOH IP grab crosses the line. Any developer who goes to the SOH understanding the T&C will leave their best ideas at home. No one wants to give away their good ideas for nothing.
The Sydney Opera House is not the first example of a hackathon abuse nor will it be the last – but it highlights the wrong thinking that many businesses seem to have about hackathons – that hackathons are a way to get stuff built quickly and cheaply. So here’s some unsolicited advice to businesses thinking about holding hackathons from someone who’s been to lots of them and has seen how they work.
Hackathons are not competitions – Hackers love to build stuff. We build apps, we build web sites, we build hardware gizmos, we build musical instruments. Hacking is all about being creative and building stuff. Nothing fosters creativity more than being in a room full of other like-minded folks. Folks that share your passion for building cool stuff. At a hackathon such as a Music Hack Day, the emphasis is not on prizes, the emphasis is on creativity. At a Music Hack Day hackers form teams spontaneously to build stuff. They share ideas with each other, they help each other – they revel in every cool demo. If you throw a big prize into the mix the dynamic changes dramatically. The hackathon becomes a competition. Hackers become developers that are thinking strategically about how to win the prize. They don’t share ideas with others, they don’t go for the creative but risky idea – they go for the conservative idea and spend their extra energy making nice colors and fonts in the PowerPoint presentation for the demo. In the early days of the Music Hack Day, we had one event where a big local sponsor brought a $10K cash prize. Not knowing any better, we went with it, but that was a mistake. Yes, there were lots of hackers and lots of completed projects, but the whole vibe of the hackathon was different. The hackathon was no longer a center of creative sharing, instead it was a cut-throat event. The goal was no longer about being creative, the goal was to win $10K . We learned our lesson and now we make sure that prizes offered at Music Hack Days are modest. Note that there are some really good hackathons like HackerOlympics that are designed to be competitions. These hackathons value teams that can think quickly and creatively across a wide range of skill sets. Winners get bragging rights and modest prizes.
Don’t use a hackathon as a way to develop your app – no one wants to go to a hackathon to do work for someone else. Hackers want to scratch their own creative itch , they don’t want to build your app for you. No amount of free pizza is going to change that. Now, if you’ve got a million dollars to spend, I’m sure you’ll get some good apps but that’s not the kind of hackathon I’d really want to go to.
Bottom line – if your hackathon has a T&C that requires developers to give up any rights to the stuff they’ve created at your hackathon you are doing it wrong. If you are going to give away big prizes, don’t expect to have a creative, sharing atmosphere – if you give away big prizes expect to see people spend more time working on a powerpoint and less time on that creative but risky hack. The currency at a hackathon should be creativity, not money or prizes and at the end of it all, the creators should own their own ideas. No amount of pizza should change that.

Children of the Hack (Angry Birds Edition)
Posted by Paul in data, events, hacking, Music, music hack day, The Echo Nest on November 18, 2013
I’m writing this post from Espoo Finland which is home to three disruptive brands: Nokia, who revolutionized the mobile phone market in the 1990s with its GSM technology; Rovio, who brought casual gaming to the world with Angry Birds; and Children of Bodom perhaps one of the most well known melodic death metal bands. So it is not surprising that Espoo is a place where you will find a mix of high tech, playfulness and hard core music – which is exactly what I found this past weekend at the Helsinki Music Hack Day hosted at the Startup Sauna in Espoo Finland.

At the Helsinki Music Hack Day, dozens of developers gathered to combine their interest in tech and their passion for music in a 24 hour hacking session to build something that was music related. Representatives from tech companies such as SoundCloud, Spotify and The Echo Nest joined the hackers to provide information about their technologies and guidance in how to use their APIs.
After 24 hours, a dozen hacks were demoed in the hour-long demo session. There was a wide range of really interesting hacks. Some of my favorites are highlighted here:
Cacophony – A multi-user remote touch controlled beat data sequencer. This hack used the Echo Nest (via the nifty new SoundCloud/Echo Nest bridge that Erik and I built on the way to Espoo), to analyze music and then allow you to use the beats from the analyzed song to create a 16 step sequencer. The sequencer can be controlled remotely via a web interface that runs on an iPad. This was a really nice hack, the resulting sequences sounded great. The developer, Pekka Toiminen used music from his own band Different Toiminen which has just released their first album. You can see the band and Pekka in the video:
[youtube http://www.youtube.com/watch?v=nLwrTf5JQ5U]It was great getting to talk to Pekka, I hope he takes his hack further and makes an interactive album for his band.
Hackface & Hackscan – by hugovk – This is a pretty novel set of hacks. Hackface takes the the top 100 or 1000 artists from your listening history on Last.fm, finds photos of the artists (via the Echo Nest API), detects faces using a face detection algorithm, intelligently resizes them and composites them into a single image giving you an image of what your average music artist in your listening history looks like.

Hackscan – takes a video and summarizes it intelligently into a single image by extracting single columns of pixels from each frame. The result is a crazy looking image that captures the essence of the video.
Hugo was a neat guy with really creative ideas. I was happy to get to know him.
Stronger Harder Faster Jester – Tuomas Ahva and Valtteri Wikstrom built the first juggling music hack that I’ve seen in the many hundreds of hack demos I’ve witnessed over the years. Their hack used three bluetooth-enabled balls that when thrown triggered music samples.

Photo via @tuomasahvra
The juggler juggles the balls in time with the music and the ball tossing triggers music samples that align with the music. The Echo Nest analysis is used to extract the salient pitch info for the aligment. It was a really original idea and great fun to watch and listen to. This hack won the Echo Nest prize.

µstify – This is the classic boy meets girl story. Young man at his first hackathon meets a young woman during the opening hours of the hackathon.

They decide to join forces and build a hack (It’s Instagram for Music!) and two days later they are winning the hackathon! Alexandra and Arian built a nifty hack that builds image filters (in the style of Instagram) based upon what the music sounds like. They use The Echo Nest to extract all sorts of music parameters and use these to select image filters. Check out their nifty presentation.
Gig Voter – this Spotify app provides a way for fans to get their favorite artists to come to their town. Fans from a town express an interest in an artist. Artists get a tool or helping them plan their tour based on information about where their most active fans actually are as well as helping them sell gigs to location owners by being able to prove that there is demand for them to perform at a certain location. Gig Voter uses Echo Nest data to help with the search and filtering.
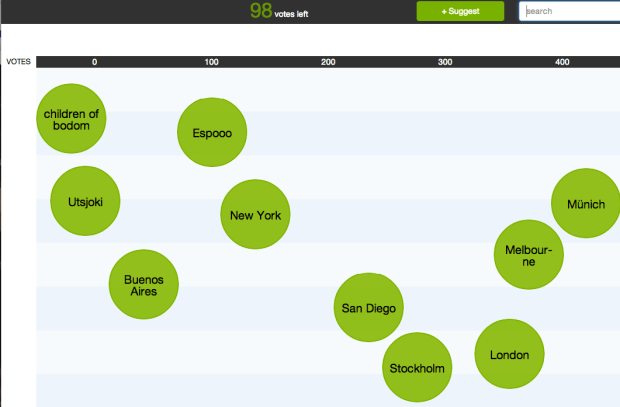
Hit factory – Hit Factory is a generative music system that creates music based upon your SoundCloud tastes and adapts that music based upon your feedback . Unfortunately, no samples of the music are to be found online, but take my word, they were quite interesting – not your usual slightly structured noise.
Abelton Common Denominator – a minimal, mini-moog style interface to simplify the interaction with Abelton – by Spotify’s Rikard Jonsson.

Swap the Drop – this was my hack. You can read more about it here.
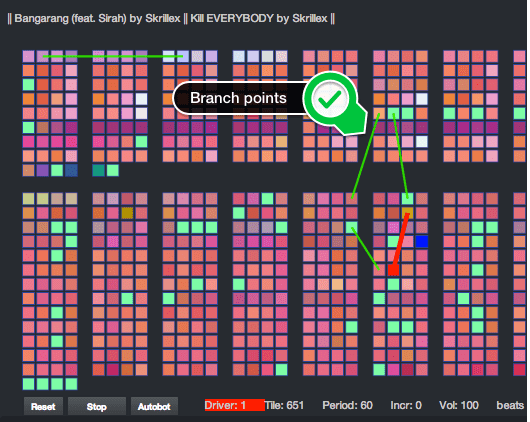
One unusual aspect of this Music Hack Day was that a couple of teams that encountered problems and were unable to finish their hacks still got up and talked about their failures. It was pretty neat to see hardcore developers get up in front of a room full of their peers and talk about why they couldn’t get Hadoop to work on their terrabyte dataset or get their party playlister based on Meteor to run inside Spotify.

I’ve enjoyed my time in Espoo and Helsinki. The Hack Day was really well run. It was held in a perfect hacking facility called the Startup Sauna.

There was plenty of comfortable hacking spots, great wifi, and a perfect A/V setup.

@sferik in a classic hacking position
The organizers kept us fed with great food (Salmon for lunch!), great music, including a live performance by Anni.

Anni performs. Photo by @sferik
There was plenty of Angry Birds Soda.

Many interesting folks to talk to …

Thanks to Lulit and the rest of the Aaltoes team for putting together such a great event.

Swap the Drop
Posted by Paul in code, data, events, fun, hacking, Music, music hack day, The Echo Nest on November 17, 2013
I’ve been in Helsinki this weekend (which is not in Sweden btw) for the Helsinki Music Hack Day. I wanted to try my hand at a DJ app that will allow you to dynamically and interactively mix two songs. I started with Girl Talk in a Box, ripped out the innards and made a whole bunch of neat changes:
- You can load more than one song at a time. Each song will appear as its own block of music tiles.
- You can seamlessly play tiles from either song.
- You can setup branch points to let you jump from an point in one song to any point in another (or the same) song.
- And the killer feature – you can have two active play heads allowing you to dynamically interact with two separate audio streams. The two play heads are always beat matched (the first play head is the master that sets the tempo for everyone else). You can cross-fade between the two audio streams – letting you move different parts of the song into the foreground and the background.
All the regular features of Girl Talk in a Box are retained – bookmarks, arrow key control, w/a/s/d navigation and so on. See the help for more details on the controls.
You can try the app here: Swap the Drop
