Archive for category code
The Echo Nest Cocoa Framework
Posted by Paul in code, Music, The Echo Nest, web services on July 1, 2009
Kamel Makhloufi (aka melka) has created a Cocoa Framework for the Echo Nest and has released it as open source. This framework makes it easy for Mac developers (and presumable iPhone and iTouch developers) to use the Echo Nest API services. Kamel’s goal is to build an application similar to Audiosurf (a music-adapting puzzle racer that uses your own music), but along the way Kamel realized his framework may be useful to others and so he has released it for all of us to use.
The Framework supports all of the Track/Analysis methods of the API including Track Upload, getting tempos, duration, bar, beat and tatum info as well as detailed segment information. On Melka’s TODO list is to add the Echo Nest artist methods.
Using the framework, Melka created a nifty track visualization tool that will render a colorful representation of the Echo Nest analysis for a track:
 Kamel implemented this in about 300 lines of Objective-C code.
Kamel implemented this in about 300 lines of Objective-C code.
The Echo Nest Cocoa Framework is released under a GPL V3 license and is hosted on google code at: http://code.google.com/p/echonestcocoaframework/.
The release is just in time for Music Hackday – I’m hoping we see an iPhone app or two emerge from this event that use the Echo Nest APIs! Kamel’s framework is just the thing to make it happen
(== (+ “Clojure” “Echo Nest”) “woah!”)
Posted by Paul in code, Music, The Echo Nest on June 25, 2009
Here’s the first Echo Nest application (as far as I know) that is written in Clojure: Another reason I like Clojure
New Echo Nest Java client released
Posted by Paul in code, java, Music, The Echo Nest, web services on June 24, 2009
We’ve just released version 1.1 of the Echo Nest Java Client. The Java Client makes it easy to access the Echo Nest APIs from a Java program. This release fixes some bugs and improves caching support. Here’s a snippet of Java code that shows how you can use the API to find similar artists for the band ‘Weezer’:
ArtistAPI artistAPI = new ArtistAPI(MY_ECHO_NEST_API_KEY);
List<Artist> artists = artistAPI.searchArtist("Weezer, false);
if (artists.size() > 0) {
for (Artist artist : artists) {
List<Scored<Artist>> similars =
artistAPI.getSimilarArtists(artist, 0, 10);
for (Scored<Artist> simArtist : similars) {
System.out.println(" " + simArtist.getItem());
}
}
}
Also included in the release is a command line shell that lets you interact with the Echo Nest API. You can start it up from the command line like so:
java -DDECHO_NEST_API_KEY=YOUR_API_KEY -jar EchoNestAPI.jar
Here’s an example session:
Welcome to The Echo Nest API Shell type 'help' nest% help 0) alias - adds a pseudonym or shorthand term for a command 1) chain - execute multiple commands on a single line 2) delay - pauses for a given number of seconds 3) echo - display a line of text 4) enid - gets the ENID for an arist 5) gc - performs garbage collection 6) getMaxCacheTime - gets the cache time 7) get_audio - gets audio for an artist 8) get_blogs - gets blogs for an artist 9) get_fam - gets familiarity for an artist 10) get_hot - gets hotttnesss for an artist 11) get_news - gets news for an artist 12) get_reviews - gets Reviews for an artist 13) get_similar - finds similar artists 14) get_similars - finds similar artists to a set of artists 15) get_urls - gets Reviews for an artist 16) get_video - gets video for an artist ( .. commands omitted ..) 53) trackTatums - gets the tatums of a track 54) trackTempo - gets the overall Tempo of a track 55) trackTimeSignature - gets the overall time signature of a track 56) trackUpload - uploads a track 57) trackUploadDir - uploads a directory of tracks 58) trackWait - waits for an analysis to be complete 59) version - displays version information nest% nest% get_similar weezer Similarity for Weezer 1.00 The Smashing Pumpkins 0.50 Ozma 0.33 Fountains of Wayne 0.25 Jimmy Eat World 0.20 Veruca Salt 0.17 The Breeders 0.14 Nerf Herder 0.13 The Flaming Lips 0.11 Death Cab for Cutie 0.10 Rivers Cuomo 0.09 The Rentals 0.08 Size 14 0.08 Nada Surf 0.07 Third Eye Blind 0.07 Chopper One nest% nest% get_fam Decemberists Familiarity for The Decemberists 0.8834854 nest% nest% trackUpload "09 When I'm Sixty-Four.MP3" ID: baad7cab21b853ea5ead4db0a12b1df8 nest% trackDuration Duration: 157.96104 nest% nest% trackTempo 140.571 (0.717) nest%
If you are interested in playing around with the Echo Nest API but don’t want to code up your own application, typing in webservice URLs by hand gets pretty old, pretty quickly. The Echo Nest shell gives you a simpler way to try things out.
Music HackDay is coming …
Posted by Paul in code, fun, Music, The Echo Nest, web services on June 23, 2009
If you live within a couple hundred miles of London, and you read this blog, then there’s no reason why you shouldn’t be planning on going to Music Hackday being held on July 11th and 12th at the Guardian offices in London. This is a great opportunity to connect with other developers that are creating next generation music applications, web sites, and gadgets. In addition to the developers, API providers will be showing off their wares (and some will even be unveiling new APIs). Companies include 7digital, Gigulate, Last.fm, People’s Music Store, Songkick, Soundcloud and The Echo Nest. Recently added to the agenda are workshops by Tinker.it and RjDj.
The Echo Nest will be there, represented by Adam Lindsay. He’ll guide you through using our various APIs including our artist recommendation APIs and our music analysis and remix APIs. Oh, and the developer that creates the coolest thing that uses the Echo Nest API will go home with a big, fat (i.e. 32gb) iPod touch.
Looking at the attendee list, the Music Hackday looks to be a who’s who in music tech – not only will it be a day of hacking, but it’s a great place to get to meet all of the folks that are creating the next generation of music apps. It looks like spaces are filling up quickly, so if you haven’t already registered, don’t dally, or you may miss out.
Where’s the Pow?
This morning, while eating my Father’s day bagel, I got to play some more with the video aspects of the Echo Nest remix API. The video remix is pretty slick. You use all of the tools that you use in the audio remix, except that the object you are manipulating has a video component as well. This makes it easy to take an audio remix and turn it into a video remix. For instance, here’s the remix code to create a remix that includes the first beat of every bar:
audiofile = audio.LocalAudioFile(input_filename)
collect = audio.AudioQuantumList()
for bar in audiofile.analysis.bars:
collect.append(bar.children()[0])
out = audio.getpieces(audiofile, collect)
out.encode(output_filename)
To turn this into a video remix, just change the code to:
av = video.loadav(input_filename)
collect = audio.AudioQuantumList()
for bar in av.audio.analysis.bars:
collect.append(bar.children()[0])
out = video.getpieces(av, collect)
out.save(output_filename)
The code is nearly identical, differing in loading and saving, while the core remix logic stays the same.
To make a remix of a YouTube video, you need to save a local copy of the video. I’ve been using KeepVid to save local flv (flash video format) of any Youtube video.
Today I played with the track ‘Boom Boom Pow’ by the Black Eyed Peas. It’s a fun song for remix because it has a very strong beat, and already has a remix feel to it. And since the song is about digital transformation, it seems to be a good target for remix experiments. (and just maybe they won’t mind the liberties I’ve taken with their song).
Here’s the original (click through to YouTube to watch it since embedding is not allowed):
Just Boom
The first remix is to only include the first beat of every measure. The code is this:
for bar in av.audio.analysis.bars: collect.append(bar.children()[0])
Just Pow
Change the beat included from beat zero to beat three, and we get something that sounds very different:
Pow Boom Boom
Here’s a version with the beats reversed. The core logic for this transformation is one line of code:
av.audio.analysis.beats.reverse()
The 5/4 Version
Here’s a version that’s in 5/4 – to make this remix I duplicated the first beat and swapped beats 2 and 3. This is my favorite of the bunch.
These transformations are of the simplest variety, taking just a couple of minutes to code and try out. I’m sure some budding computational remixologist could do some really interesting things with this API.
Note that the latest video support is not in the main branch of remix. If you want to try some of this out you’ll need to check out the bl-video branch from the svn repository. But this is guaranteed to be rolled into the main branch before the upcoming Music Hackday. Update: the latest video support is now part of the main branch. If you want to try it out, check it out from the trunk of the SVN repository. So download the code, grab your API key and start remixing.
Update: As Brian pointed out in the comments there was some blocking on the remix renders. This has been fixed, so if you grab the latest code, the video output quality is as good as the input.
More confusing than Memento
Posted by Paul in code, fun, remix, The Echo Nest on June 20, 2009
Ben Lacker, one of our leading computational remixologists here at the Echo Nest has been improving the video remix capabilities of the Echo Nest remix API. On Friday, he remixed this mind blower. It’s Coldplay’s music video for ‘The Scientist’ – beat reversed, which means that song is played in reverse order beat by beat (but each beat is still played in forward order). Since Coldplay’s video is already shot in reverse order, the resulting video has a story that unfolds in proper chronological order, but where every second of video runs backwards, while the music unfolds in reverse chronological order while every beat runs forward. I get a little bit of a stomachache watching this video.
Ben has committed the code for this remix to the Echo Nest remix code samples so feel free to check it out and hack on it. I hope to see some more interesting music and video remixes coming out of the upcoming Music Hackday.
Music Hackday is coming
Posted by Paul in code, fun, The Echo Nest on June 11, 2009

Open your calendars and reserve July 11th and 12th for Music Hackday for 24 plus hours of solid music hacking in the heart of London. Music Hackday is a chance for developers to get together and share ideas and code while building a music application using the music APIs from companies like Last.fm, 7digital, Gigulate, People’s Music Store, SongKick, SoundCloud and The Echo Nest. This looks to be a really fun event.
The Echo Nest remix 1.0 is released!
Posted by Paul in code, fun, Music, remix, The Echo Nest, web services on May 12, 2009
Version 1.0 of the Echo Nest remix has been released. Echo Nest Remix is an open source SDK for Python that lets you write programs that manipulate music. For example, here’s a python function that will take all the beats of a song, and reverse their order:
def reverse(inputFilename, outputFilename):
audioFile = audio.LocalAudioFile(inputFilename)
chunks = audioFile.analysis.beats
chunks.reverse()
reversedAudio = audio.getpieces(audioFile, chunks)
reversedAudio.encode(outputFilename)
When you apply this to a song by The Beatles you get something that sounds like this:
which is surprisingly recognizable, musical – and yet different from the original.
Quite a few web apps have been written that use remix. One of my favorites is DonkDJ, which will ‘put a donk‘ on any song. Here’s an example: Hung Up by Madonna (with a Donk on it):
This is my jam lets you create mini-mixes to share with people.

And where would the web be without the ability to add more cowbell to any song.
There’s lots of good documentation already for remix. Adam Lindsay has created a most excellent overview and tutorial for remix. There’s API documentation and there’s documentation for the underlying Echo Nest web services that perform the audio analysis. And of course, the source is available too.
So, if you are looking for that fun summer coding project, or if you need an excuse to learn Python, or perhaps you are a budding computational remixologist download remix, grab an API key from the Echo Nest and start writing some remix code.
Here’s one more example of the fun stuff you can do with remix. Guess the song, and guess the manipulation:
moot wins, Time Inc. loses
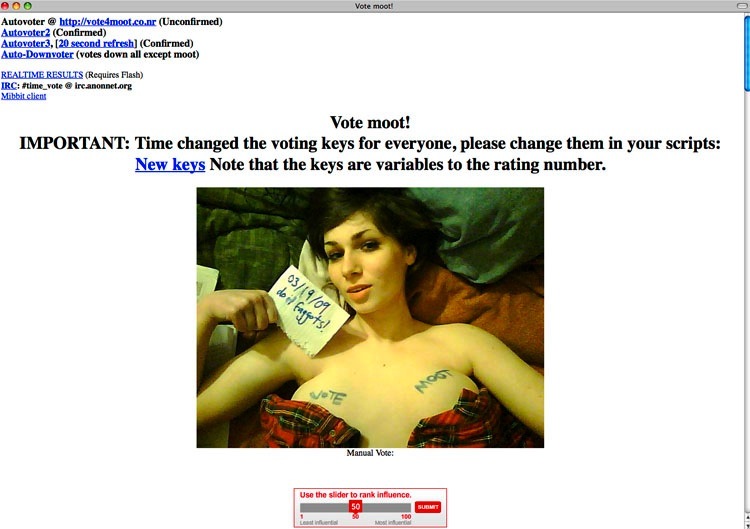
![]() This morning Time.com published the final result for their annual TIME 100 Poll. Time reports that the new owner of the title ‘Worlds’s most influential person, is moot’. What TIME doesn’t say is that their poll was so totally manipulated that the results of the poll are not an indication of who is the most influential, but instead they stand as a monument to Time’s incompetence.
This morning Time.com published the final result for their annual TIME 100 Poll. Time reports that the new owner of the title ‘Worlds’s most influential person, is moot’. What TIME doesn’t say is that their poll was so totally manipulated that the results of the poll are not an indication of who is the most influential, but instead they stand as a monument to Time’s incompetence.

Looking at the poll results we see clear evidence of the hack. The first letters of the top 21 finalists in the poll spell out ‘Marblecake, also the game’. Evidence of precision hackery for anyone to see. And yet, Time says they rebuffed all attempts to hack the poll. Quoting from the time article: “TIME.com’s technical team did detect and extinguish several attempts to hack the vote”. Which leads me to wonder whether Time.com is being dishonest or is just plain incompetent. Considering Hanlon’s razor , I have to go with incompetence. (And if you have any doubt about Time’s incompetence, take a close look at the Poll. Notice that Oprah Winfrey and Ratan Tata have the exact same number of votes. That’s because they both shared the same ID in the poll. A vote for either one was a vote for the other. Same goes for Michael Bloomberg and Gustavo Dudamel. If you vote for one, you vote for the other.)
How did the hack happen? I’ve already described in great detail the steps that the loose collective known as ‘Anonymous’ took to hack the poll. This group (that gathered on an IRC channel at anonnet.org) probed for weaknesses in the poll protocols and wrote autovoters to stuff the ballot box with votes that would put the candidates in the proper order to spell out the Message, adapting as necessary whenever Time adjusted its protocol in a meager attempt to keep the hackers out. But two weeks ago, Time got serious about poll security. They modified the poll so that you needed to prove that you were human (via a captcha) in order to vote.

This instantly shut down all of the autovoters. Anonymous was offline – no longer able to submit thousands of votes per minute. And what’s worse, when the autovoters were shutdown, the Message ‘Marblecake, also the game’ soon decayed into a meaningless “mablre caelakosteghamm”. It seemed that Time.com had won – the Message would not survive the next two weeks of voting. But Anonymous didn’t give up, they considered it a challenge to restore the Message. Here’s how they did it.
Update -4/29 Professor Luis von Ahn, the project lead for reCAPTCHA, sent me a very polite email suggesting that I change a few words here to make it clear to a casual reader that reCAPTCHA was not hacked. I agree that the original post could be easily misinterpreted by a casual reader, so I’ve changed a couple of words here and there to make it absolutely clear that reCAPTCHA was not compromised for the Time Poll.
First attempt – trying (and failing) to crack reCAPTCHA
The first thing Anonymous tried to do was tried to break reCAPTCHA, the captcha technology used by Time.com. They built a program that would analyze the images, break the words into characters and apply OCR to the images in an attempt to automate the captcha process. However, unsurprisingly, it proved to be too difficult of a task – certainly that was a nut that would take more than a week to crack. So after a few days, they abandoned this approach.

Second Attempt: trying (and failing) to hack reCAPTCHA – ‘The Penis Flood’
The next tactic used was to see if they could find a flaw in the reCAPTCHA implementation. One thing they discovered about reCAPTCHA was that it always presents two words to a user for decoding – one word is a control word known by the reCAPTCHA system, while the other is an unknown word (reCAPTCHA uses the humans to help correct OCR errors). Wikipedia describes the process: “Scanned text is subjected to analysis by two different optical character recognition programs; in cases where the programs disagree, the questionable word is converted into a CAPTCHA. The word is displayed along with a control word already known and is labeled by the human. Those words that are consistently given a single label by human judges are recycled as control words”.  What Anonymous realized was that if they always labeled the unknown scanned text with the same word – and if they did this thousands and thousands of times eventually a large percentage of the unknown words would be mislabeled with their word. All they had to do was look at the two words in the captcha, enter the proper label for the ‘easy’ one (presumably that would be the one that the two optical scanners would agree upon) and enter the word “penis” for the hard one. If they did this often enough, then soon a significant percentage of the images would be labeled as ‘penis’ and the ability to autovote would be restored (one side effect, that was not lost on Anonymous, was the notion that for years to come there would be a number of digital books with the word ‘penis’ randomly inserted throughout the text. Update: I asked Ben Maurer, chief engineer of reCAPTCHA about this ‘penis flood‘ attack, Ben says that they’ve anticipated this type of attack and they have numerous protections that will keep the penises from penetrating the reCAPTCHA barrier. Update – 4/29 – Luis von Ahn, the project lead of reCAPTCHA goes on to say ” about the “penis attack”. We serve over 400 million CAPTCHAs per week, so submitting 200k CAPTCHAS with the word penis doesn’t even come close to poisoning our database — we serve each word to multiple random users, and we require them to be correct on the other word, so to get any traction with this attack, they would have had to submit at least 100 times more CAPTCHAs. And even if they did this, we have many other measures against it. That attack simply doesn’t work.”
What Anonymous realized was that if they always labeled the unknown scanned text with the same word – and if they did this thousands and thousands of times eventually a large percentage of the unknown words would be mislabeled with their word. All they had to do was look at the two words in the captcha, enter the proper label for the ‘easy’ one (presumably that would be the one that the two optical scanners would agree upon) and enter the word “penis” for the hard one. If they did this often enough, then soon a significant percentage of the images would be labeled as ‘penis’ and the ability to autovote would be restored (one side effect, that was not lost on Anonymous, was the notion that for years to come there would be a number of digital books with the word ‘penis’ randomly inserted throughout the text. Update: I asked Ben Maurer, chief engineer of reCAPTCHA about this ‘penis flood‘ attack, Ben says that they’ve anticipated this type of attack and they have numerous protections that will keep the penises from penetrating the reCAPTCHA barrier. Update – 4/29 – Luis von Ahn, the project lead of reCAPTCHA goes on to say ” about the “penis attack”. We serve over 400 million CAPTCHAs per week, so submitting 200k CAPTCHAS with the word penis doesn’t even come close to poisoning our database — we serve each word to multiple random users, and we require them to be correct on the other word, so to get any traction with this attack, they would have had to submit at least 100 times more CAPTCHAs. And even if they did this, we have many other measures against it. That attack simply doesn’t work.”
Third Attempt: Optimizing reCAPTCHA entry
As appealing as the notion of sprinkling the word ‘penis’ into texts, the Anonymous team knew that the clock was ticking, and if they were going to restore the Message they didn’t have time to wait for the autovoters to come back online – they were going to have to vote manually, many, many times. And so they needed to be able to enter captcha’s as fast as they could. They developed a set of guidelines that allowed them to quickly decide which reCAPTCHA words they could skip. For example:
You will be given 2 words: 1 real, 1 fake.
For [REAL FAKE] or [FAKE REAL], you can just type in REAL and it should be accepted.
If it’s [LOOKSREAL LOOKSREAL] or [LOOKSFAKE LOOKSFAKE], it’s usually just quicker to just type in both words. Don’t waste precious time deciding which one of them is real.
Use both the appearance and the type of word to identify a fake
word. Don’t rely on just one of them.
The whole ruleset is here: fake captcha
By understanding how reCAPTCHA worked – the team was able to double their productivity (since they usually only had to enter one word instead of two). To further optimize their voting they created a poll front-end that allowed you to enter votes quickly while giving you an update of the poll status (and since it is a 4chan kind of crowd, they also provided the option to stream some porn just to keep you company while you are subverting one of the largest media companies in the world.

They found that with this version of the manual loader, the thing that was taking the most time was loading the captcha images, so they made a bare bones version that loaded 3 captchas at a time, in the background eliminating this bottleneck, and doubling their manual voting speed once more (and showing them vote per minute stats).

Update – Just to be perfectly clear, anon didn’t hack reCAPTCHA. It did exactly what it was supposed to do. It shut down the auto voters instantly and effectively. The only option left after Time added reCAPTCHA to the poll was a brute force attack. Ben Maurer, (chief engineer on reCAPTCHA) comments on the hack: “reCAPTCHA put up a hard to break barrier that forced the attackers to spend hundreds of hours to obtain a relatively small number of votes. reCAPTCHA prevented numerous would-be attackers from engaging in an attack. In any high-profile system, it’s important to implement reCAPTCHA as part of a larger defense-in-depth strategy”. As Dr. von Ahn points out “had Time used reCAPTCHA from the beginning, this would have never happened — anon submitted *tens of millions* of votes before Time added reCAPTCHA, but they were only able to submit ~200k afterwards. And to do this, they had to resort to typing the CAPTCHAs by hand!” One thing that Time inc. did that made it much easier for the anonymous hack was to allow leave the door open for cross-site request forgeries which allowed anon to create a streamlined poll that never had to fetch data from Time.com.
Brute Force
With the streamlined manual voting process, a single, motivated voter could cast 30 votes per minute (perhaps only 20 VPM if they were watching porn). But some calculations showed that they needed about 200K votes to cast to get everyone in their proper position. If they were going to succeed they really had to organize their votes. They churned the numbers and came up with this plan:
TOTAL VOTES NEEDED 191,209
Alexander Levedev (up to 37.5) 6,541 votes
Rick Warren (more than 1,902,130) 7,255 votes
Kobe Bryant (up to 39.50) 109,174 votes
Sheikh Ahmed bin Zayed Al Nahyan (up to 35.50) 5,000 votes
Hu Jintao (up to 31.50) 19,836 votes
Elizabeth Warren (up to 27.50) 43,403 votes
With a sprinkling of help from folks on /b/, the core team of about a dozen got down to manual voting. (To get help from /b/ they put together info on how to streamline the captcha process, how to configure the browser to mask referrals, deal with proxies and provided some other (perhaps not-safe-for work incentives). Some of the most hardcore voters (I call them ‘devoters’) spent 40+ hours voting. At their peak, they were casting about 200 votes per minute (compared to the many, many thousands per minute that they could cast via autovoter before Time added the captcha).
With 200k votes to cast, they knew it would be close, and they didn’t know exactly when the polls were closing. In the final days the crew was getting demotivated. But one boost to their productivity and morale occurred when they sussed out how Time actually did the final ordering (they round the average rating to the nearest rating, and then use the total number of votes to break a tie). With this little nugget of information, they were able to redistribute how they voted, eliminating the need for about 30K of the 200K votes. They discovered a few more quirks in how Time.com ranked the candidates which allowed them to shave even more votes off the required total for a total savings of 46k votes. With these vote savings, the goal was close at hand, with their boosted morale they were able to push across the finish line.
The End Game
Finally, on Friday, Time closed the poll, but funny thing was they didn’t turn off the polling URLs, so even though you couldn’t vote through the official Time.com website, it was still possible to vote via the streamlined manual voter – and so the ballot stuffing continued. On Saturday afternoon, the message was restored, but the voting continued – as the team tried to gain a cushion of safety, should voters for other candidates mess things up at the last minute. Early morning on April 27th Time.com published the results. And there, for the whole world to see was the message, completely intact,”mARBLECAKE ALSO THE GAME”.

Celebrations were in order – there was cake

and happy faces

and a general sigh of relief from the group.
It is 12 hours after Time.com poll has been closed. The mood among Anonymous is high – the hack was completed, it is there for the world to see. Time.com behaved as expected – they refused to acknowledge the hack and the Message – but the word is out there. People are reading about the hack on 4chan, Reddit and Digg – people know that the poll was hacked and they know that Anonymous is responsible. They started with a goal and despite some rather severe setbacks were able to meet that goal
From where I sit, I really have to wonder about Time.com. They spent their time promoting and running this poll that they know (or should know) is a total farce. They give a wink and nudge to the questionable results by saying “This is an Internet poll. Doubting the results is kind of the point.” Which is just stupid. Perhaps the point should be “if you want to maintain any kind of journalistic integrity, don’t conduct online polls”.
So what’s next for Anonymous? One hacker (knowing the stereotype people have for an Anonymous hacker) says “we’re going to resume masturbating and being the total failures that we are “. When I asked Zombocom, the mastermind of the Message , if he had any message for moot – the man that they put on top of the world – Zombocom replied: ‘ “The Game” – but still, enjoy it.’
Update: A mini-interview with moot:
A friend put me in touch with moot so I could ask him about the hack. Since he’s so influential I kept my questions short and to the point. Here’s the mini-interview:
Time makes a joke a your expense (“To put the magnitude of the upset in perspective, it’s worth noting that everyone Moot beat out actually has a job. “). Any response to Time magazine about this:
I wasn’t offended by the blurb on TIME.com. To clarify, I never claimed to be unaware of the “concerted plan to influence the poll,” just that I hadn’t instructed anybody to vote for me. They did it all on their own (as you already know).
Time also indicates that they rebuffed the attempts to hack the poll. (“TIME.com’s technical team did detect and extinguish several attempts to hack the vote. “). This seems to me to be a lie. Likewise, they ignore the ‘marblecake, also the game’ message completely. Anything to say about this?
Honestly, I think Time had as much fun with the poll as we all did. It drove a lot of traffic to their site, and after the final results were released, generated a lot of buzz about the upcoming issue.
There’s a group of a dozen or so guys who’ve devoted a couple of months to this. Anything to say to them?
As for a response to the players: “Thanks.”
Update 10/24/2012:
Ukraine translation by Gmail Archive – http://www.stoodio.org/moot-wins-time-inc-loses.
libre.fm – what’s the point?
Posted by Paul in code, data, Music, recommendation, web services on April 24, 2009
 Libre.fm is essentially an open source clone of Last.fm’s audioscrobbler. With Libre.fm you can scrobble your music play behavior to a central server, where your data is aggregated with all of the other scrobbles and can be used to create charts, recommendations, playlists – all the sorts of things we see at Last.fm. As the name implies, everything about Libre.fm is free. All the Libre.fm code is released under the GNU AGPL. You can run your own server. You own your own data.
Libre.fm is essentially an open source clone of Last.fm’s audioscrobbler. With Libre.fm you can scrobble your music play behavior to a central server, where your data is aggregated with all of the other scrobbles and can be used to create charts, recommendations, playlists – all the sorts of things we see at Last.fm. As the name implies, everything about Libre.fm is free. All the Libre.fm code is released under the GNU AGPL. You can run your own server. You own your own data.
The Libre project is just getting underway. Not only is paint is not dry, they’ve only just put down the drop cloth, got the brushes ready and opened the can. Right now there’s a minimal scrobbler server (called GNUkebox) that will take anyone’s scrobbles and adds them to a postgres database. This server is compatible with Last.fm’s so nearly all scrobbling clients will scrobble to Libre.fm. (Note that to get many clients to work you actually have to modify your /etc/hosts file to redirect outgoing connections that would normally go to post.audioscrobbler.com so that they go to the libre.fm scrobbling machine. It is a clever way to get instant support for Libre.fm by lots of clients, but I must admit I feel a bit dirty lying to my computer about where to send the scrobbles.)
Another component of Libre.fm is the web front end (called nixtape) that shows what people are playing, what is popular, artist charts and clouds. (Imagine what Audioscrobbler.com looked like in 2005). Here’s my Libre.fm page:
 There is already quite a lot of functionality on the web front end – there are (at least minimal) user, artist, album and track pages. However, there are some critical missing bits – perhaps most significant of these is the lack of a recommender. The only discovery tool so far at Libre.fm is the clickable ‘Explore popular artist’ cloud:
There is already quite a lot of functionality on the web front end – there are (at least minimal) user, artist, album and track pages. However, there are some critical missing bits – perhaps most significant of these is the lack of a recommender. The only discovery tool so far at Libre.fm is the clickable ‘Explore popular artist’ cloud:

Libre.fm has only been live for a few week – but it is already closing in on its millionth scrobble. As I write this, about 340K tracks have been scrobbled by 2011 users with a total of 920052 plays. (Note that since Libre.fm lets you import your Last.fm listening history, many of these plays have been previously scrobbled at Last.fm).
When you compare these numbers to Last.fm’s, Libre.fm’s numbers are very small – but if you consider the very short time that it has been live, these numbers start to look pretty good. What is even more important is that Libre.fm has already built a core team of over two dozen developers. Two dozen developers can write a crazy amount of code in a short time – so I’m expecting to see the gaps in Libre.fm functionality to be filled rather quickly. And as the gaps in functionality are eliminated, more users will come (especially those users who’ve recently abandoned Last.fm when Last.fm started to charge users that don’t live in the U.S., U.K. or Germany).
I remember way back in 1985 reading this article in Byte magazine about this seemingly crazy guy named Richard Stallman who was creating his own operating system called GNU. I couldn’t understand why he was doing it. We already had MS-DOS and Unix (I was using DEC’s Ultrix at the time which was a mighty fine OS). I didn’t think we needed anything else. But Stallman was on a mission – that mission was to create free software. Software that you were free to run, free to modify, free to distribute. I was wrong about Stallman. His set of tools became key parts of Linux and his ideas about ‘CopyLeft’ enabled the open source movement.
When I first heard about Libre.fm, my reaction was very similar to my reaction back in 1985 to Stallman – what’s the point? Last.fm already provides all these services and much more. Last.fm lets you get access to your data via their web services. Last.fm already has billions of scrobbles from millions of users. Why do we need another Last.fm? But this time I’m prepared to be wrong. Perhaps we don’t really want our data held by one company. Perhaps a community of passionate developers can take the core concept of the audioscrobbler to somewhere new. Just as Stallman’s crazy idea has changed the way we think about developing software, perhaps Libre.fm is the begining of the next revolution in music discovery.
Update – I asked mattl, founder of libre.fm, what his motivation for creating libre.fm is. He says there are two prime motivations:
- Artistic – “I wants to support libre musicians. To give them a platform where they are the ruling class.”
- freedom – “give everyone access to their data, so even if they don’t like what we’re doing with libre music, the software is still free (to them and us)”

{kind=link}