Posts Tagged maps
Anti-preferences in regional listening
Posted by Paul in data, The Echo Nest, zero ui on February 28, 2014
In previous posts, we’ve seen that different regions of the country can have different listening preferences. So far we’ve looked at the distinctive artists in any particular region. Perhaps equally interesting is to look at artists that get much fewer listens in a particular region than you would expect. These are the regional anti-preferences, the artists that are generally popular across the United States, but get much less love in a particular part of the country.
To find these artists, we merely look for artists that drop the furthest in rank on the top-most-played chart for a region when compared to the whole U.S. For example, we can look at the top 50 artists in the United States, and find those artists of the 50 that drop furthest in rank on the New Hampshire chart. Try it yourself. Here are the results:
Artists listened to more in United States than they are in New Hampshire
| # | Artist | Rank in United States |
Rank in New Hampshire |
Delta |
|---|---|---|---|---|
| 1 | R. Kelly | 42 | 720 | -678 |
| 2 | 2Pac | 45 | 243 | -198 |
| 3 | Usher | 46 | 205 | -159 |
| 4 | Coldplay | 36 | 155 | -119 |
| 5 | Chris Brown | 37 | 120 | -83 |
R. Kelly is ranked the 42nd most popular artist in the U.S., but in New Hampshire he’s the 720th most popular, a drop of 678 positions on the chart making him the most ignored artist in New Hampshire.
We can do this for each of the states in the United States and of course we can put them on a map. Here’s a map that shows the most ignored artist of the U.S. top-50 artist in each state.
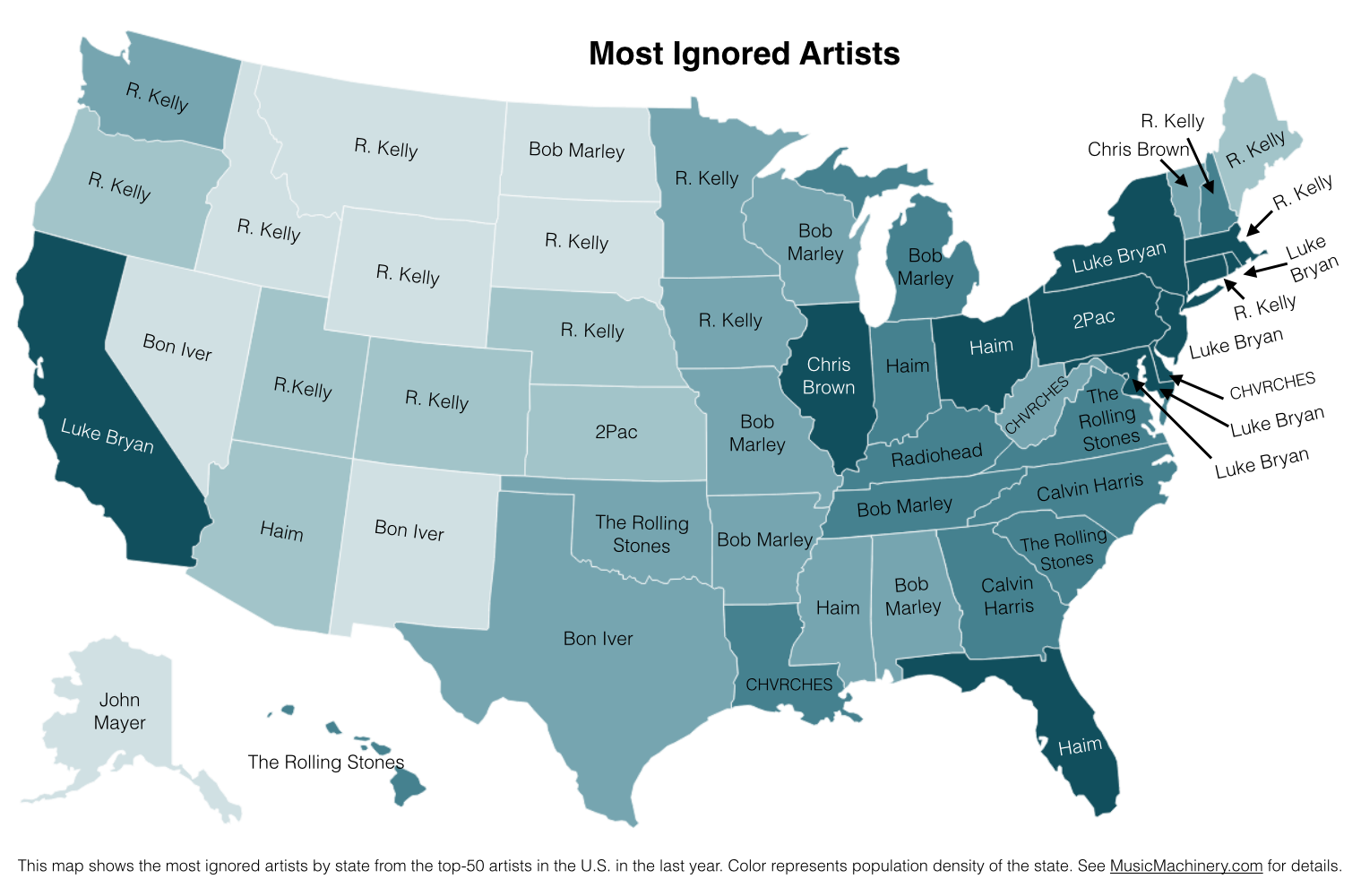
What can we do with this information? If we know where a music listener lives, but we know nothing else about them, we can potentially improve their listening experience by giving them music based upon their local charts instead of the global or national charts. We can also improve the listening even if we don’t know where the listener is from. As we can see from the map, certain artists are polarizing artists, liked in some circles and disliked in others. If we eliminate the polarizing artists for a listener that we know nothing about, we can reduce the risk of musically offending the listener. Of course, once we know a little bit about the music taste of a listener we can greatly improve their recommendations beyond what we can do based solely on demographic info such as the listener location.
Future work There are a few more experiments that I’d like to try with regard to exploring regional preferences. In particular I think it’d be fun to generate an artist similarity metric based solely on regional listening behaviors. In this world, Juicy J, the southern rapper, and Hillsong United, the worship band would be very similar since they both get lots of listens from people in Memphis. A few readers have suggested alternate scoring algorithms to try, and of course it would be interesting to repeat these experiments for other parts of the world. So much music data, so little time! However, this may be the last map I make for a while since the Internet must be getting sick of ‘artists on a map’ by now.
Credit and thanks to Randal Cooper (@fancycwabs) for creating the first set of anti-preference maps. Check out his blog and the Business Insider article about his work.
The data for the map is drawn from an aggregation of data across a wide range of music services powered by The Echo Nest and is based on the listening behavior of a quarter million online music listeners.
Favorite Artists vs Distinctive Artists by State
In my recent regional listening preferences post I published a map that showed the distinctive artists by state. The map was rather popular, but unfortunately was a source of confusion for some who thought that the map was showing the favorite artist by state. A few folks have asked what the map of favorite artists per state would look like and how it would compare to the distinctive map. Here are the two maps for comparison.
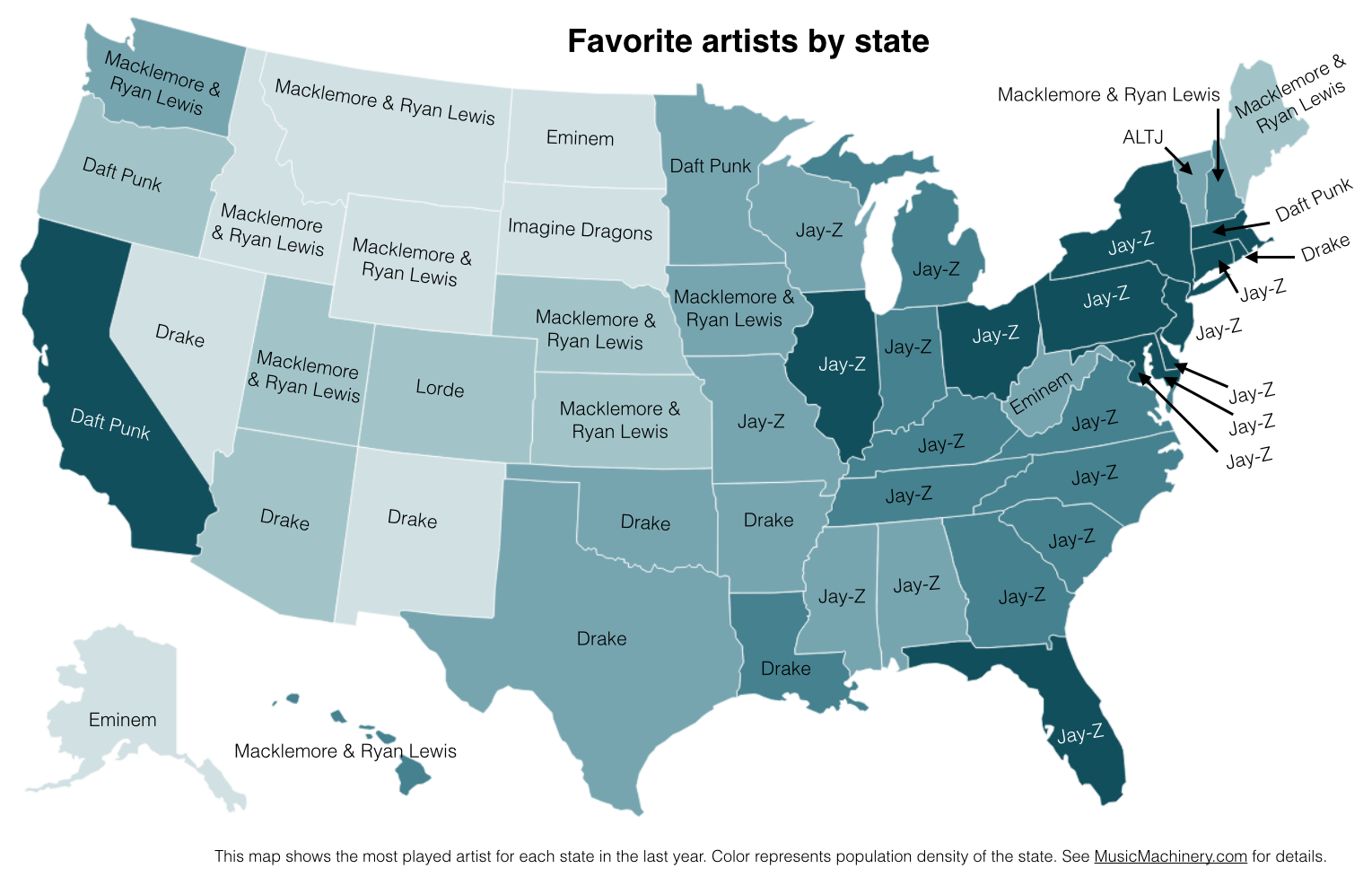
Favorite Artists by State
This map shows the most played artist in each state over the last year. It is interesting to see the regional differences in favorite artists and how just a handful of artists dominates the listening of wide areas of the country.
Most Distinctive Artists by State
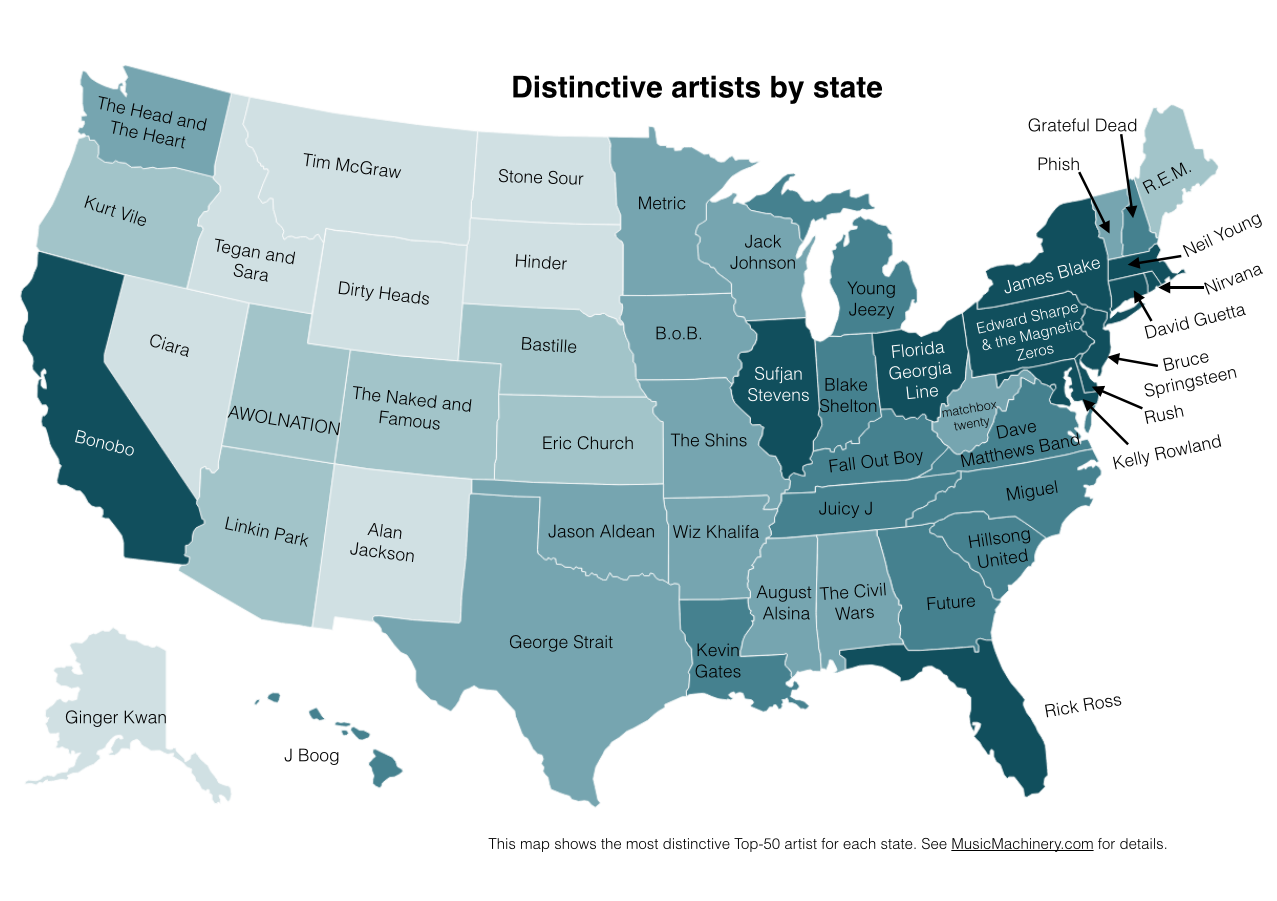
This is the previously published map that shows the artists that are listened to proportionally more frequently in a particular state than they are in all of the United States.
The data for both maps is drawn from an aggregation of data across a wide range of music services powered by The Echo Nest and is based on the listening behavior of a quarter million online music listeners.
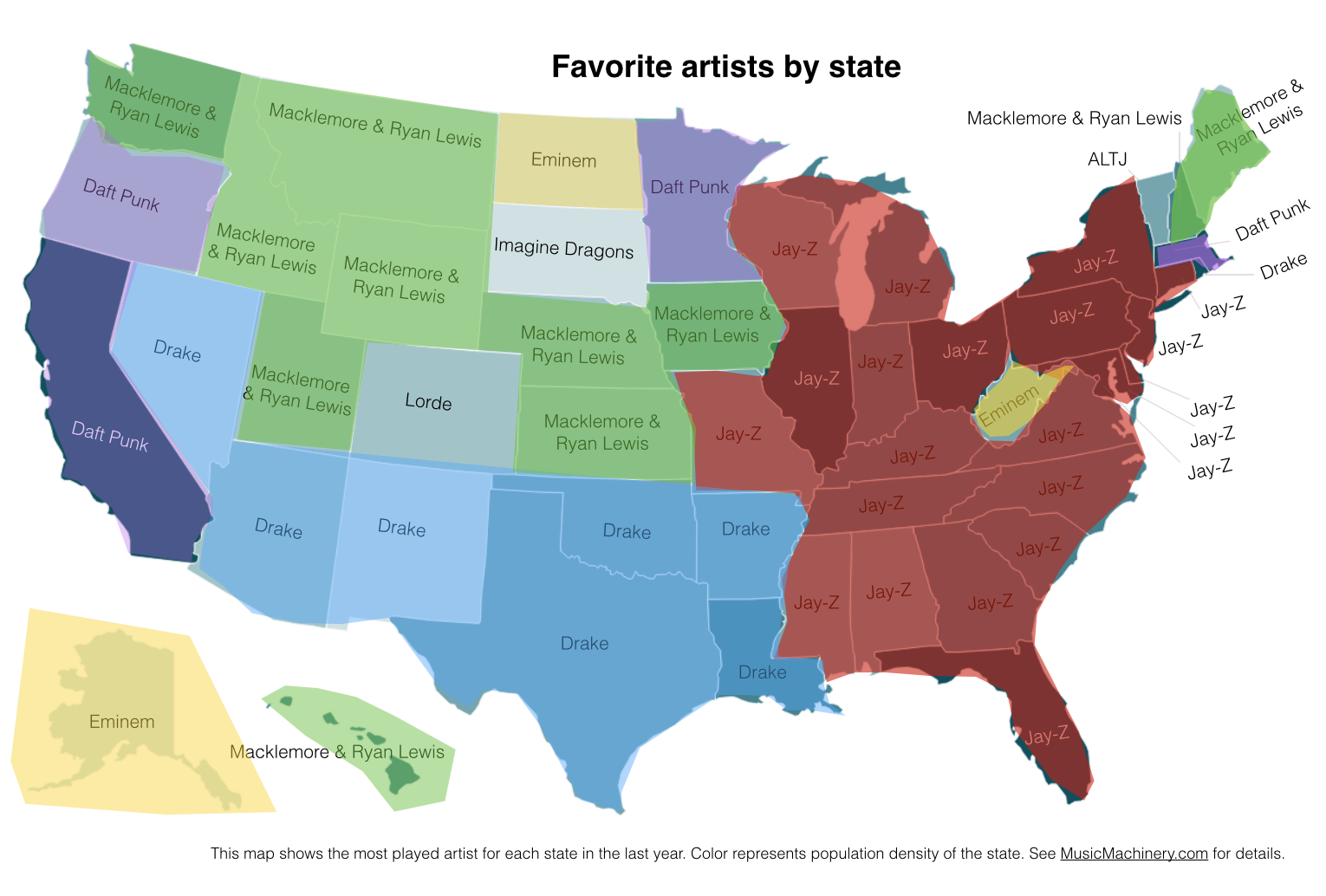
It is interesting to see that even when we consider just the most popular artists, we can see regionalisms in listening preferences. I’ve highlighted the regions with color on this version of the map:
Favorite Artist Regions
Building a music map
Posted by Paul in data, fun, java, Music, research, The Echo Nest, visualization, web services on May 31, 2009
I like maps, especially maps that show music spaces – in fact I like them so much I have one framed, hanging in my kitchen. I’d like to create a map for all of music. Like any good map, this map should work at multiple levels; it should help you understand the global structure of the music space, while allowing you to dive in and see fine detailed structure as well. Just as Google maps can show you that Africa is south of Europe and moments later that Stark st. intersects with Reservoir St in Nashua NH a good music map should be able to show you at a glance how Jazz, Blues and Rock relate to each other while moments later let you find an unknown 80s hair metal band that sounds similar to Bon Jovi.
My goal is to build a map of the artist space, one the allows you to explore the music space at a global level, to understand how different music styles relate, but then also will allow you to zoom in and explore the finer structure of the artist space.
I’m going to base the music map on the artist similarity data collected from the Echo Nest artist similarity web service. This web service lets you get 15 most similar artists for any artist. Using this web service I collected the artist similarity info for about 70K artists along with each artists familiarity and hotness.
Some Explorations
It would be silly to start trying to visualize 70K artists right away – the 250K artist-to-artist links would overwhelm just about any graph layout algorithm. The graph would look like this. So I started small, with just the near neighbors of The Beatles. (Beatles-K1) For my first experiment, I graphed the the nearest neighbors to The Beatles. This plot shows how the the 15 near neighbors to the Beatles all connect to each other.

In the graph, artist names are sized proportional to the familiarity of the artist. The Beatles are bigger than The Rutles because they are more familiar. I think the graph is pretty interesting, showing how all of the similar artists of the Beatles relate to each other, however, the graph is also really scary because it shows 64 interconnections for these 16 artists. This graph is just showing the outgoing links for the Beatles, if we include the incoming links to the Beatles (the artist similarity function is asymettric so outgoing similarities and incoming similarities are not the same), it becomes a real mess:

If you extend this graph one more level – to include the friends of the friends of The Beatles (Beatles-K2), the graph becomes unusable. Here’s a detail, click to see the whole mess. It is only 116 artists with 665 edges, but already you can see that it is not going to be usable.



Eliminating the edges
Clearly the approach of drawing all of the artist connections is not going to scale to beyond a few dozen artists. One approach is to just throw away all of the edges. Instead of showing a graph representation, use an embedding algorithm like MDS or t-SNE to position the artists in the space. These algorithms layout items by attempting to minimize the energy in the layout. It’s as if all of the similar items are connected by invisible springs which will push all of the artists into positions that minimize the overall tension in the springs. The result should show that similar artists are near each other, and dissimilar artists are far away. Here’s a detail for an example for the friends of the friends of the Beatles plot. (Click on it to see the full plot)

I find this type of visualization to be quite unsatisfying. Without any edges in the graph I find it hard to see any structure. I think I would find this graph hard to use for exploration. (Although it is fun though to see the clustering of bands like The Animals, The Turtles, The Byrds, The Kinks and the Monkeee).
Drawing some of the edges
We can’t draw all of the edges, the graph just gets too dense, but if we don’t draw any edges, the map loses too much structure making it less useful for exploration. So lets see if we can only draw some of the edges – this should bring back some of the structure, without overwhelming us with connections. The tricky question is “Which edges should I draw?”. The obvious choice would be to attach each artist to the artist that it is most similar to. When apply this to the Beatles-K2 neighborhood we get something like this:

This clearly helps quite a bit. We no longer have the bowl of spaghetti, while we can still see some structure. We can even see some clustering that make sense (Led Zeppelin is clustered with Jimi Hendrix and the Rolling Stones while Air Supply is closer to the Bee Gees). But there are some problems with this graph. First, it is not completely connected, there are a 14 separate clusters varying from a size of 1 to a size of 57. This disconnection is not really acceptable. Second, there are a number of non-intuitive flows from familiar to less familiar artists. It just seems wrong that bands like the Moody Blues, Supertramp and ELO are connected to the rest of the music world via Electric Light Orchestra II (shudder).
To deal with the ELO II problem I tried a different strategy. Instead of attaching an artist to its most similar artist, I attach it to the most similar artist that also has the closest, but greater familiarity. This should prevent us from attaching the Moody Blues to the world via ELO II, since ELO II is of much less familiarity than the Moody Blues. Here’s the plot:

Now we are getting some where. I like this graph quite a bit. It has a nice left to right flow from popular to less popular, we are not overwhelmed with edges, and ELO II is in its proper subservient place. The one problem with the graph is that it is still disjoint. We have 5 clusters of artists. There’s no way to get to ABBA from the Beatles even though we know that ABBA is a near neighbor to the Beatles. This is a direct product of how we chose the edges. Since we are only using some of the edges in the graph, there’s a chance that some subgraphs will be disjoint. When I look at the a larger neighborhood (Beatles-K3), the graph becomes even more disjoint with a hundred separate clusters. We want to be able to build a graph that is not disjoint at all, so we need a new way to select edges.
Minimum Spanning Tree
One approach to making sure that the entire graph is connected is to generate the minimum spanning tree for the graph. The minimum spanning tree of a graph minimizes the number of edges needed to connect the entire graph. If we start with a completely connected graph, the minimum spanning tree is guarantee to result in a completely connected graph. This will eliminate our disjoint clusters. For this next graph, built the minimum spanning tree of the Beatles-K2 graph.

As predicted, we no longer have separate clusters within the graph. We can find a path between any two artists in the graph. This is a big win, we should be able to scale this approach up to an even larger number of artists without ever having to worry about disjoint clusters. The whole world of music is connected in a single graph. However, there’s something a bit unsatisfying about this graph. The Beatles are connected to only two other artists: John Lennon & The Plastic Ono Band and The Swinging Blue Jeans. I’ve never heard of the Swinging Blue Jeans. I’m sure they sound a lot like the Beatles, but I’m also sure that most Beatles fans would not tie the two bands together so closely. Our graph topology needs to be sensitive to this. One approach is to weight the edges of the graph differently. Instead of weighting them by similarity, the edges can be weighted by the difference in familiarity between two artists. The Beatles and Rolling Stones have nearly identical familiarities so the weight between them would be close to zero, while The Beatles and the Swinging Blue Jeans have very different familiarities, so the weight on the edge between them would be very high. Since the minimum spanning is trying to reduce the overall weight of the edges in the graph, it will chose low weight edges before it chooses high weight edges. The result is that we will still end up with a single graph, with none of the disjoint clusters, but artists will be connected to other artists of similar familiarity when possible. Let’s try it out:

Now we see that popular bands are more likely to be connected to other popular bands, and the Beatles are no longer directly connected to “The Swinging Blue Jeans”. I’m pretty happy with this method of building the graph. We are not overwhelmed by edges, we don’t get a whole forest of disjoint clusters, and the connections between artists makes sense.
Of course we can build the graph by starting from different artists. This gives us a deep view into that particular type of music. For instance, here’s a graph that starts from Miles Davis:

Here’s a near neighbor graph starting from Metallica:

And here’s one showing the near neighbors to Johann Sebastian Bach:

This graphing technique works pretty well, so lets try an larger set of artists. Here I’m plotting the top 2,000 most popular artists. Now, unlike the Beatles neighborhood, this set of artists is not guaranteed to be connected, so we may have some disjoint cluster in the plot. That is expected and reasonable. The image of the resulting plot is rather large (about 16MB) so here’s a small detail, click on the image to see the whole thing. I’ve also created a PDF version which may be easier to browse through.

I pretty pleased with how these graphs have turned out. We’ve taken a very complex space and created a visualization that shows some of the higher level structure of the space (jazz artists are far away from the thrash artists) as well as some of the finer details – the female bubblegum pop artists are all near each other. The technique should scale up to even larger sets of artists. Memory and compute time become the limiting factors, not graph complexity. Still, the graphs aren’t perfect – seemingly inconsequential artists sometimes appear as gateways into whole sub genre. A bit more work is needed to figure out a better ordering for nodes in the graph.
Some things I’d like to try, when I have a bit of spare time:
- Create graphs with 20K artists (needs lots of memory and CPU)
- Try to use top terms or tags of nearby artists to give labels to clusters of artists – so we can find the Baroque composers or the hair metal bands
- Color the nodes in a meaningful way
- Create dynamic versions of the graph to use them for music exploration. For instance, when you click on an artist you should be able to hear the artist and read what people are saying about them.
To create these graphs I used some pretty nifty tools:
- The Echo Nest developer web services – I used these to get the artist similarity, familiarity and hotness data. The artist similarity data that you get from the Echo Nest is really nice. Since it doesn’t rely directly on collaborative filtering approaches it avoids the problems I’ve seen with data from other sources of artist similarity. In particular, the Echo Nest similarity data is not plagued by hubs (for some music services, a popular band like Coldplay may have hundreds or thousands of near neighbors due to a popularity bias inherent in CF style recommendation). Note that I work at the Echo Nest. But don’t be fooled into thinking I like the Echo Nest artist similarity data because I work there. It really is the other way around. I decided to go and work at the Echo Nest because I like their data so much.
- Graphviz – a tool for rendering graphs
- Jung – a Java library for manipulating graphs
If you have any ideas about graphing artists – or if you’d like to see a neighborhood of a particular artist. Please let me know.

{kind=link}