Archive for category code
Echo Nest Radio on Spotify
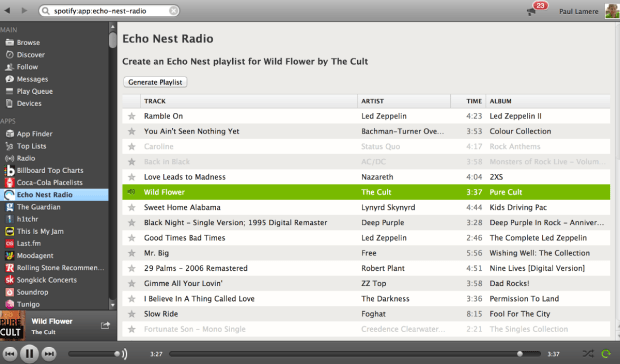
I work for Spotify now – so for my Sunday morning programming project I thought I’d write a simple Spotify App that uses The Echo Nest API to create playlists based upon a seed song. I’ve done this before, but the last time was a few years ago and the Spotify Apps API has changed quite a bit since then, so I thought I’d use this as an opportunity to freshen my understanding of the Spotify API as well as to demonstrate how to write a Spotify App that uses The Echo Nest API.
I created an Echo Nest Radio app – it is a very simple app – it looks at what song you are currently playing and will generate an Echo Nest playlist based upon that seed song. The code is pretty straightforward. It grabs the Now Playing track from Spotify, gets the track’s ID and uses that as a seed for The Echo Nest song-radio static playlist API. This call returns Spotify track IDs (thanks to our Rosetta Stone ID mapping layer) that are then tossed into a temporary playlist, which is used to build a List view which is then displayed in the app. All told it is just over 100 lines of Javascript.
It did take me a bit of time to get the hang of the newer Spotify Apps API. It has changed quite a bit since I last used it and many of the examples that I relied on in the past, like Peter Watt’s excellent Kitchen Sink app, use an older version of the API. The new version has some significant changes including a nifty new module system along with a new approach to managing long-running queries that relies on promises. Once I got the hang of it, I decided that I like the new version – it makes for cleaner code and a much more efficient app since much less data needs to be moved around.
The app is on github – to use it you need to sign up for a developer account on Spotify and follow the rest of the Getting Started instructions (this means if you are not a developer, you’ll probably not be able to use the app).
The Spotify Apps API makes it super easy to be able to create apps that run inside Spotify. Its a very familiar programming environment for anyone who has done web programming. You can use all of your favorite libraries from jQuery to Lo-Dash to create really compelling apps that sit on top of the millions and millions of tracks in the Spotify catalog. However, unlike a web app where anyone can publish their app on the web, to publish a Spotify App you have to submit your app to the Spotify App approval process and only apps that Spotify approves are published. Spotify sets a high bar for what ultimately gets approved – which keeps the quality of the apps high, but also means that hacks and experiments built on the Spotify Apps platform will likely never be approved for release to the general public. It’s a difficult balancing act for Spotify. They’ve built the ultimate music hacking platform with this API, but if they open the doors to every music hack, they will ultimately dilute the listening experience of the user – like so other many App stores that are flooded with garbage apps, if they publish every app and hack then Spotify listeners would be inundated with the musical equivalent of flashlight and fart apps. With the approval process, Spotify essentially says ‘the listener comes first’ which is the right choice. Still, as a music hacker I do wish it was easier to publish rich music apps built on the Spotify platform. Luckily Spotify is committed to building an active and vibrant developer ecosystem so I don’t expect they we will be standing still.
Update 3/24/14: – I’ve added the ability to save these playlists back to Spotify, so you can take the Echo Nest radio playlists with you.
Second update 3/24/14 – note that Spotify’s recent announcement that they are closing app submissions means that you won’t be able to submit apps for publishing anymore, but you should be able to still create your own.
How the Autocanonizer works
Posted by Paul in code, data, events, fun, genre, hacking, music hack day, The Echo Nest on March 18, 2014
Last week at the SXSW Music Hack Championship hackathon I built The Autocanonizer. An app that tries to turn any song into a canon by playing it against a copy of itself. In this post, I explain how it works.
At the core of The Autocanonizer are three functions – (1) Build simultaneous audio streams for the two voices of the canon (2) Play them back simultaneously, (3) Supply a visualization that gives the listener an idea of what is happening under the hood. Let’s look at each of these 3 functions:
(1A) Build simultaneous audio streams – finding similar sounding beats
The goal of the Autocanonizer is to fold a song in on itself in such a way that the result still sounds musical. To do this, we use The Echo Nest analyzer and the jremix library to do much of the heavy lifting. First we use the analyzer to break the song down into beats. Each beat is associated with a timestamp, a duration, a confidence and a set of overlapping audio segments. An audio segment contains a detailed description of a single audio event in the song. It includes harmonic data (i.e. the pitch content), timbral data (the texture of the sound) and a loudness profile. Using this info we can create a Beat Distance Function (BDF) that will return a value that represents the relative distance between any two beats in the audio space. Beats that are close together in this space sound very similar, beats that are far apart sound very different. The BDF works by calculating the average distance between overlapping segments of the two beats where the distance between any two segments is a weighted combination of the euclidean distance between the pitch, timbral, loudness, duration and confidence vectors. The weights control which part of the sound takes more precedence in determining beat distance. For instance we can give more weight to the harmonic content of a beat, or the timbral quality of the beat. There’s no hard science for selecting the weights, I just picked some weights to start with and tweaked them a few times based on how well it worked. I started with the same weights that I used when creating the Infinite Jukebox (which also relies on beat similarity), but ultimately gave more weight to the harmonic component since good harmony is so important to The Autocanonizer.
(1B) Build simultaneous audio streams – building the canon
The next challenge, and perhaps biggest challenge of the whole app, is to build the canon – that is – given the Beat Distance Function, create two audio streams, one beat at a time, that sound good when played simultaneously. The first stream is easy, we’ll just play the beats in normal beat order. It’s the second stream, the canon stream that we have to worry about. The challenge: put the beats in the canon stream in an order such that (1) the beats are in a different order than the main stream, and (2) they sound good when played with the main stream.
The first thing we can try is to make each beat in the canon stream be the most similar sounding beat to the corresponding beat in the main stream. If we do that we end up with something that looks like this:
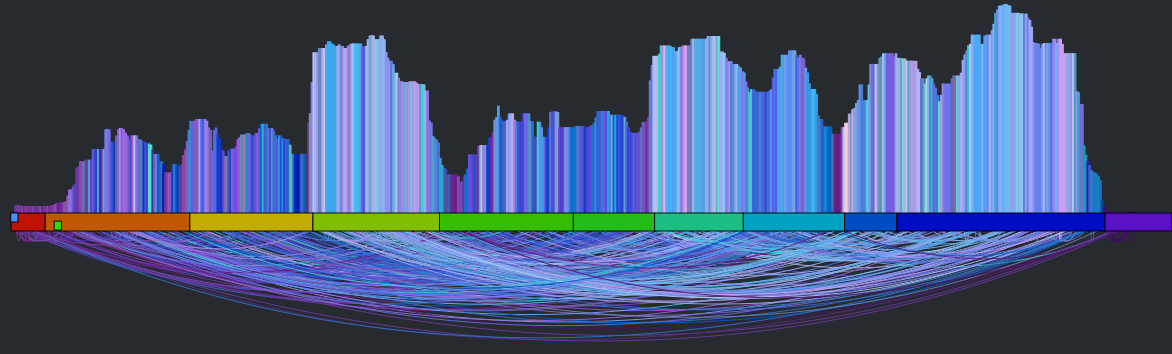
It’s a rat’s nest of connections, very little structure is evident. You can listen to what it sounds like by clicking here: Experimental Rat’s Nest version of Someone Like You (autocanonized). It’s worth a listen to get a sense of where we start from. So why does this bounce all over the place like this? There are lots of reasons: First, there’s lots of repetition in music – so if I’m in the first chorus, the most similar beat may be in the second or third chorus – both may sound very similar and it is practically a roll of the dice which one will win leading to much bouncing between the two choruses. Second – since we have to find a similar beat for every beat, even beats that have no near neighbors have to be forced into the graph which turns it into spaghetti. Finally, the underlying beat distance function relies on weights that are hard to generalize for all songs leading to more noise. The bottom line is that this simple approach leads to a chaotic and mostly non-musical canon with head-jarring transitions on the canon channel. We need to do better.
There are glimmers of musicality in this version though. Every once in a while, the canon channel will remaining on a single sequential set of beats for a little while. When this happens, it sounds much more musical. If we can make this happen more often, then we may end up with a better sounding canon. The challenge then is to find a way to identify long consecutive strands of beats that fit well with the main stream. One approach is to break down the main stream into a set of musically coherent phrases and align each of those phrases with a similar sounding coherent phrase. This will help us avoid the many head-jarring transitions that occur in the previous rat’s nest example. But how do we break a song down into coherent phrases? Luckily, it is already done for us. The Echo Nest analysis includes a breakdown of a song into sections – high level musically coherent phrases in the song – exactly what we are looking for. We can use the sections to drive the mapping. Note that breaking a song down into sections is still an open research problem – there’s no perfect algorithm for it yet, but The Echo Nest algorithm is a state-of-the-art algorithm that is probably as good as it gets. Luckily, for this task, we don’t need a perfect algorithm. In the above visualization you can see the sections. Here’s a blown up version – each of the horizontal colored rectangles represents one section:
![]()
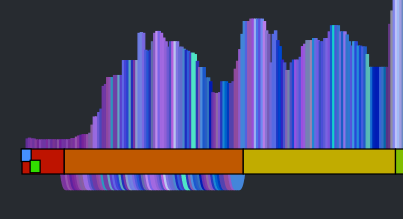
You can see that this song has 11 sections. Our goal then is to get a sequence of beats for the canon stream that aligns well with the beats of each section. To make things at little easier to see, lets focus in on a single section. The following visualization shows the similar beat graph for a single section (section 3) in the song:

You can see bundles of edges leaving section 3 bound for section 5 and 6. We could use these bundles to find most similar sections and simply overlap these sections. However, given that sections are rarely the same length nor are they likely to be aligned to similar sounding musical events, it is unlikely that this would give a good listening experience. However, we can still use this bundling to our advantage. Remember, our goal is to find a good coherent sequence of beats for the canon stream. We can make a simplifying rule that we will select a single sequence of beats for the canon stream to align with each section. The challenge, then, is to simply pick the best sequence for each section. We can use these edge bundles to help us do this. For each beat in the main stream section we calculate the distance to its most similar sounding beat. We aggregate these counts and find the most commonly occurring distance. For example, there are 64 beats in Section 3. The most common occurring jump distance to a sibling beat is 184 beats away. There are ten beats in the section with a similar beat at this distance. We then use this most common distance of 184 to generate the canon stream for the entire section. For each beat of this section in the main stream, we add a beat in the canon stream that is 184 beats away from the main stream beat. Thus for each main stream section we find the most similar matching stream of beats for the canon stream. This visualizing shows the corresponding canon beat for each beat in the main stream.

This has a number of good properties. First, the segments don’t need to be perfectly aligned with each other. Note, in the above visualization that the similar beats to section 3 span across section 5 and 6. If there are two separate chorus segments that should overlap, it is no problem if they don’t start at the exactly the same point in the chorus. The inter-beat distance will sort it all out. Second, we get good behavior even for sections that have no strong complimentary section. For instance, the second section is mostly self-similar, so this approach aligns the section with a copy of itself offset by a few beats leading to a very nice call and answer.
That’s the core mechanism of the autocanonizer – for each section in the song, find the most commonly occurring distance to a sibling beat, and then generate the canon stream by assembling beats using that most commonly occurring distance. The algorithm is not perfect. It fails badly on some songs, but for many songs it generates a really good cannon affect. The gallery has 20 or so of my favorites.
(2) Play the streams back simultaneously
When I first released my hack, to actually render the two streams as audio, I played each beat of the two streams simultaneously using the web audio API. This was the easiest thing to do, but for many songs this results in some very noticeable audio artifacts at the beat boundaries. Any time there’s an interruption in the audio stream there’s likely to be a click or a pop. For this to be a viable hack that I want to show people I really needed to get rid of those artifacts. To do this I take advantage of the fact that for the most part we are playing longer sequences of continuous beats. So instead of playing a single beat at a time, I queue up the remaining beats in the song, as a single queued buffer. When it is time to play the next beat, I check to see if is the same that would naturally play if I let the currently playing queue continue. If it is I ‘let it ride’ so to speak. The next beat plays seamlessly without any audio artifacts. I can do this for both the main stream and the canon stream. This virtually elimianates all the pops and clicks. However, there’s a complicating factor. A song can vary in tempo throughout, so the canon stream and the main stream can easily get out of sync. To remedy this, at every beat we calculate the accumulated timing error between the two streams. If this error exceeds a certain threshold (currently 50ms), the canon stream is resync’d starting from the current beat. Thus, we can keep both streams in sync with each other while minimizing the need to explicitly queue beats that results in the audio artifacts. The result is an audio stream that is nearly click free.
(3) Supply a visualization that gives the listener an idea of how the app works
I’ve found with many of these remixing apps, giving the listener a visualization that helps them understand what is happening under the hood is a key part of the hack. The first visualization that accompanied my hack was rather lame:
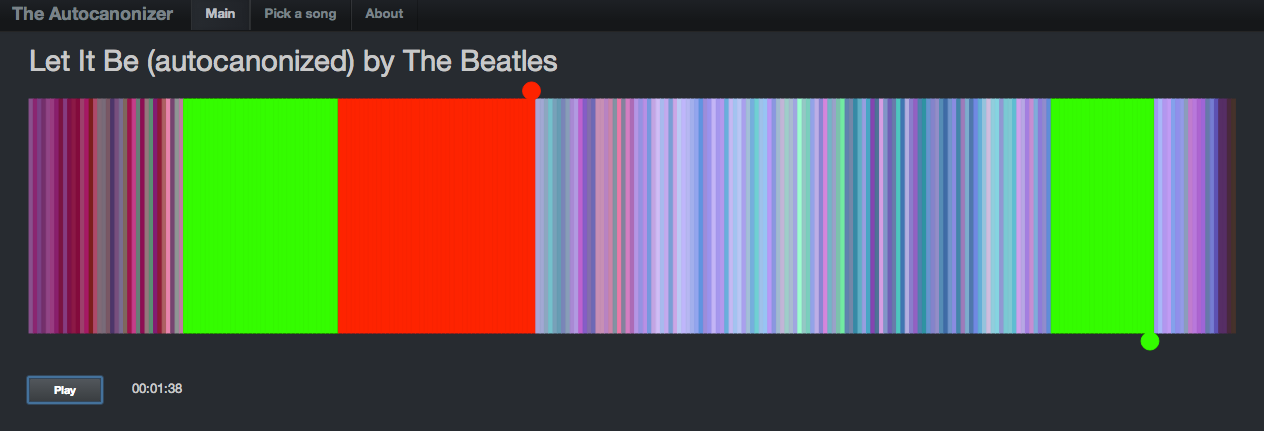
It showed the beats lined up in a row, colored by the timbral data. The two playback streams were represented by two ‘tape heads’ – the red tape head playing the main stream and the green head showing the canon stream. You could click on beats to play different parts of the song, but it didn’t really give you an idea what was going on under the hood. In the few days since the hackathon, I’ve spent a few hours upgrading the visualization to be something better. I did four things: Reveal more about the song structure, show the song sections, show, the canon graph and animate the transitions.
Reveal more about the song
The colored bars don’t really tell you too much about the song. With a good song visualization you should be able to tell the difference between two songs that you know just by looking at the visualization. In addition to the timbral coloring, showing the loudness at each beat should reveal some of the song structure. Here’s a plot that shows the beat-by-beat loudness for the song stairway to heaven.
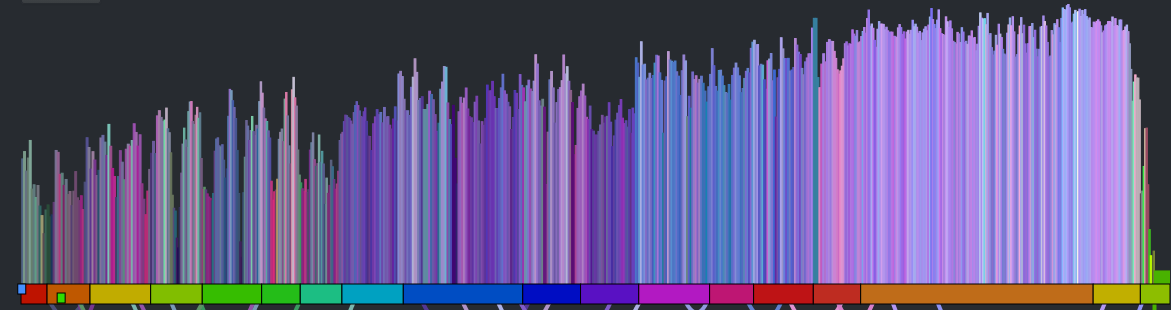
You can see the steady build in volume over the course of the song. But it is still less than an ideal plot. First of all, one would expect the build for a song like Stairway to Heaven to be more dramatic than this slight incline shows. This is because the loudness scale is a logarithmic scale. We can get back some of the dynamic range by converting to a linear scale like so:
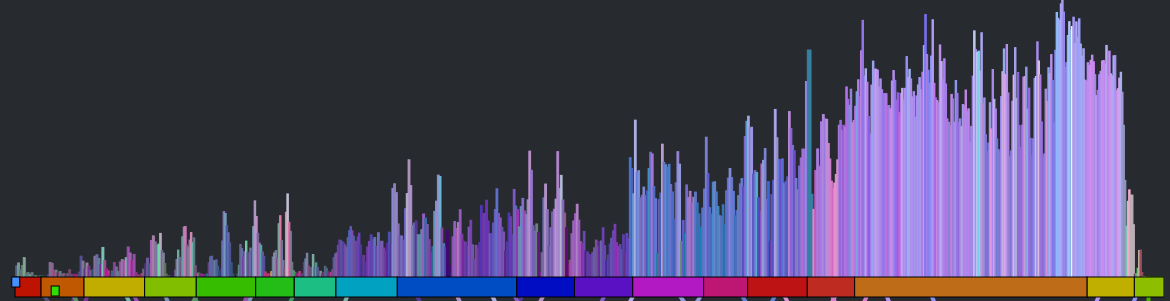
This is much better, but the noise still dominates the plot. We can smooth out the noise by taking a windowed average of the loudness for each beat. Unfortunately, that also softens the sharp edges so that short events, like ‘the drop’ could get lost. We want to be able to preserve the edges for significant edges while still eliminating much of the noise. A good way to do this is to use a median filter instead of a mean filter. When we apply such a filter we get a plot that looks like this:
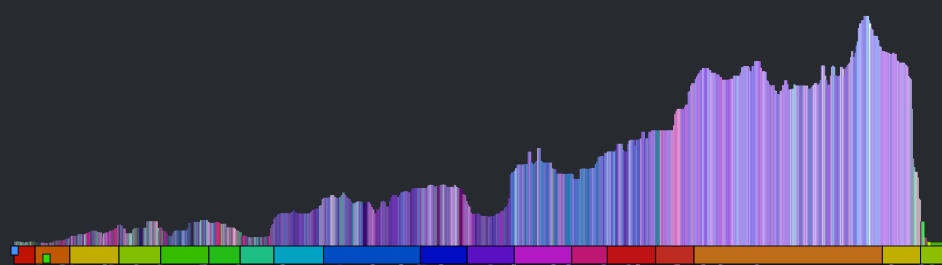
The noise is gone, but we still have all the nice sharp edges. Now there’s enough info to help us distinguish between two well known songs. See if you can tell which of the following songs is ‘A day in the life’ by The Beatles and which one is ‘Hey Jude’ by The Beatles.
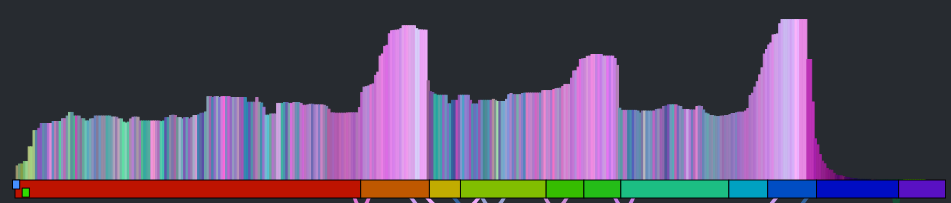
Which song is it? Hey Jude or A day in the Life?
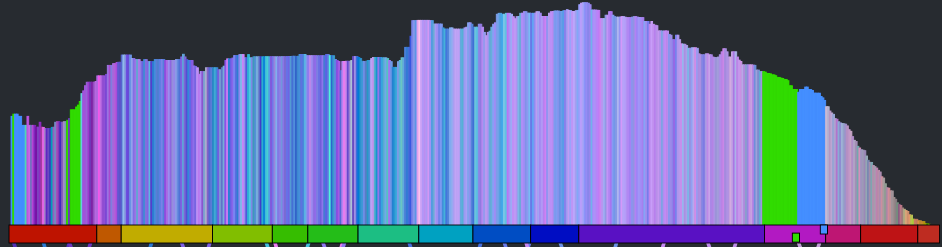
Which song is it? Hey Jude or A day in the Life?
Show the song sections
As part of the visualization upgrades I wanted to show the song sections to help show where the canon phrase boundaries are. To do this I created a the simple set of colored blocks along the baseline. Each one aligns with a section. The colors are assigned randomly.
Show the canon graph and animate the transitions.
To help the listener understand how the canon is structured, I show the canon transitions as arcs along the bottom of the graph. When the song is playing, the green cursor, representing the canon stream animates along the graph giving the listener a dynamic view of what is going on. The animations were fun to do. They weren’t built into Raphael, instead I got to do them manually. I’m pretty pleased with how they came out.

All in all I think the visualization is pretty neat now compared to where it was after the hack. It is colorful and eye catching. It tells you quite a bit about the structure and make up of a song (including detailed loudness, timbral and section info). It shows how the song will be represented as a canon, and when the song is playing it animates to show you exactly what parts of the song are being played against each other. You can interact with the vizualization by clicking on it to listen to any particular part of the canon.
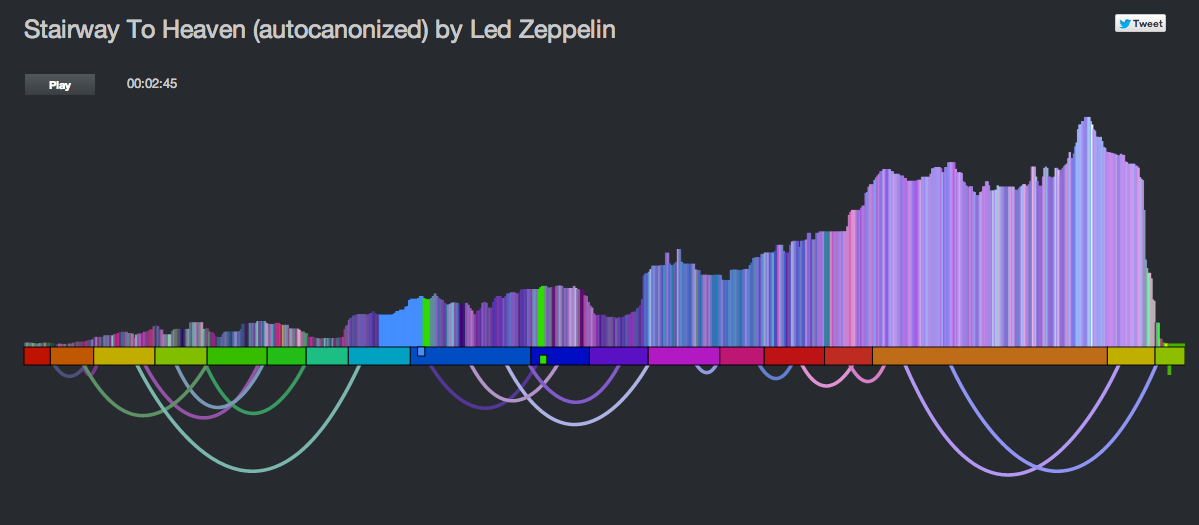
Wrapping up – this was a fun hack and the results are pretty unique. I don’t know of any other auto-canonizing apps out there. It was pretty fun to demo that hack at the SXSW Music Hack Championships too. People really seemed to like it and even applauded spontaneously in the middle of my demo. The updates I’ve made since then – such as fixing the audio glitches and giving the visualization a face lift make it ready for the world to come and visit. Now I just need to wait for them to come.
The Autocanonizer
Posted by Paul in code, events, hacking, The Echo Nest on March 13, 2014
I’ve spent the last 24 hours at the SXSW Music Hackathon championship. For my hack I’ve built something called The Autocanonizer. It takes any song and tries to make a canon out of it. A canon is a song that can be played against a copy of itself. The Autocanonizer does this by looking at the detailed audio in the song (via The Echo Nest analysis), and looks for parts of the song that might overlap well. It builds a map of all these parts and when it plays the song it plays the main audio, while overlapping it with the second audio stream. It doesn’t always work, but when it does, the results can be quite fun and sometimes quite pleasing.
To go along with the playback I created a visualization that shows the song and the two virtual tape heads that are playing the song. You can click on the visualization to hear particular bits.
There are some audio artifacts on a few songs still. I know how to fix it, but it requires some subtle math (subtraction) that I’m sure I’ll mess up right before the hackathon demo if I attempt it now, so it will have to wait for another day. Also, there’s a Firefox issue that I will fix in the coming days. Or you can go and fix all this yourself because the code is on github.
Favorite Artists vs Distinctive Artists by State
In my recent regional listening preferences post I published a map that showed the distinctive artists by state. The map was rather popular, but unfortunately was a source of confusion for some who thought that the map was showing the favorite artist by state. A few folks have asked what the map of favorite artists per state would look like and how it would compare to the distinctive map. Here are the two maps for comparison.
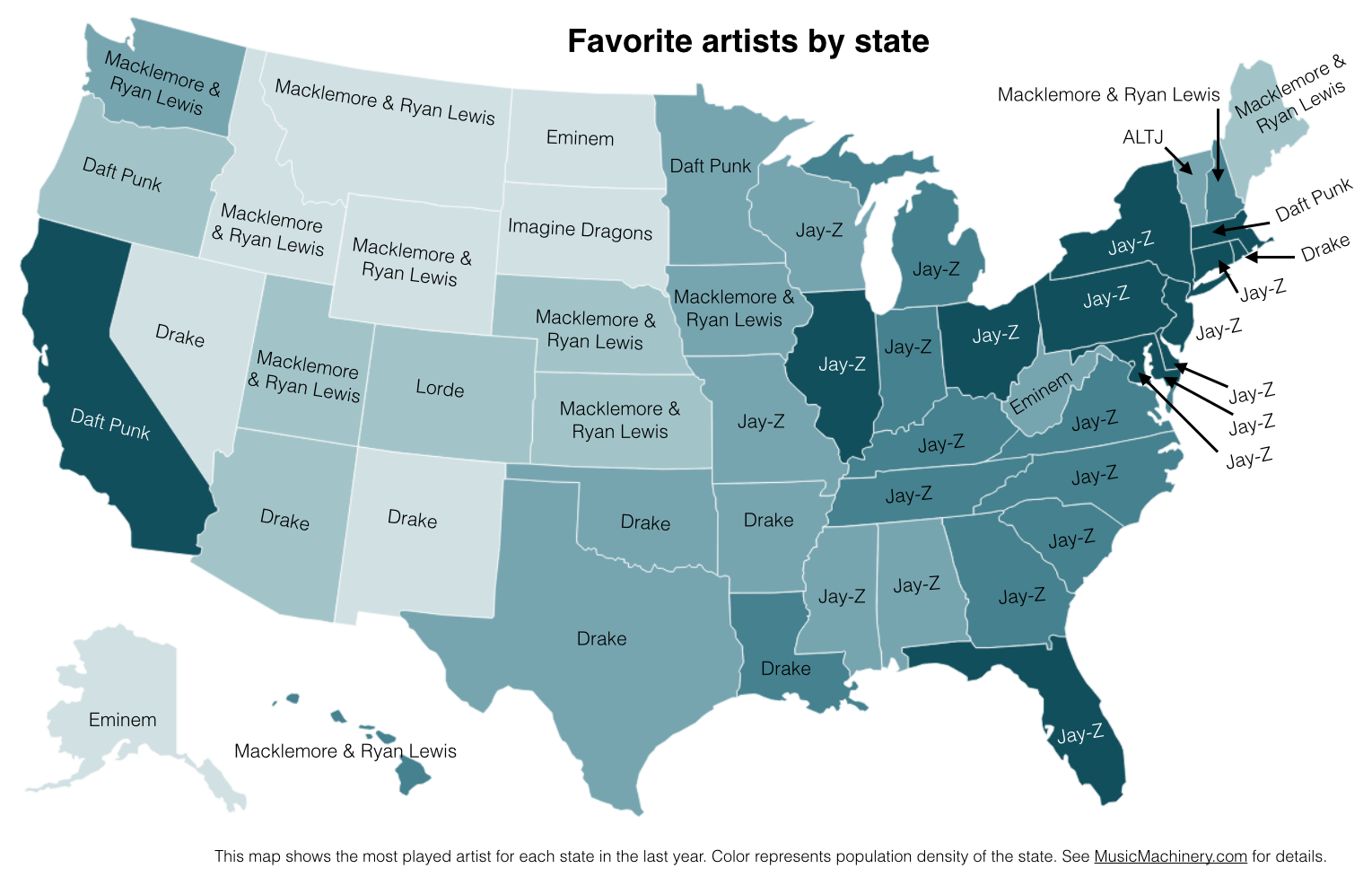
Favorite Artists by State
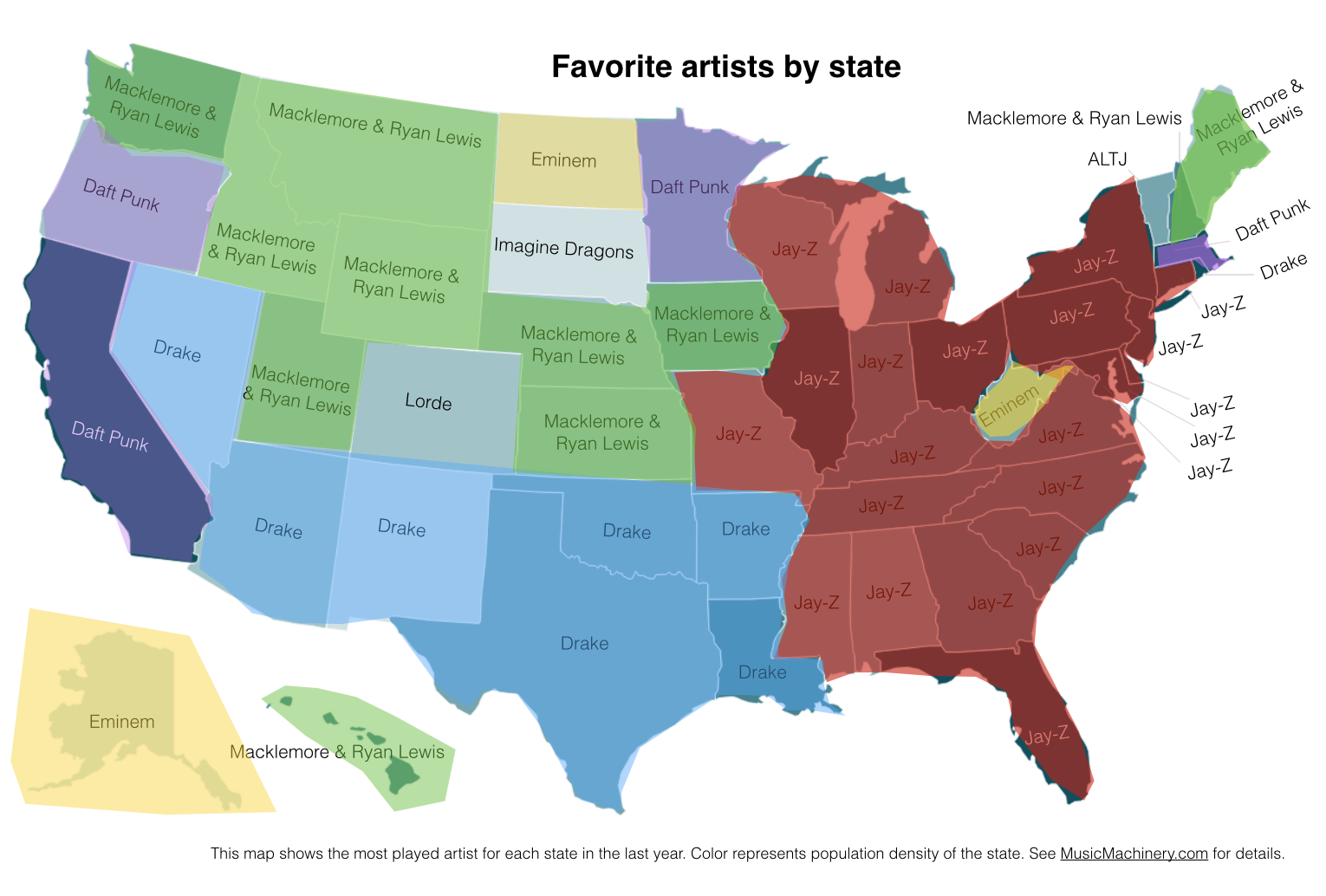
This map shows the most played artist in each state over the last year. It is interesting to see the regional differences in favorite artists and how just a handful of artists dominates the listening of wide areas of the country.
Most Distinctive Artists by State
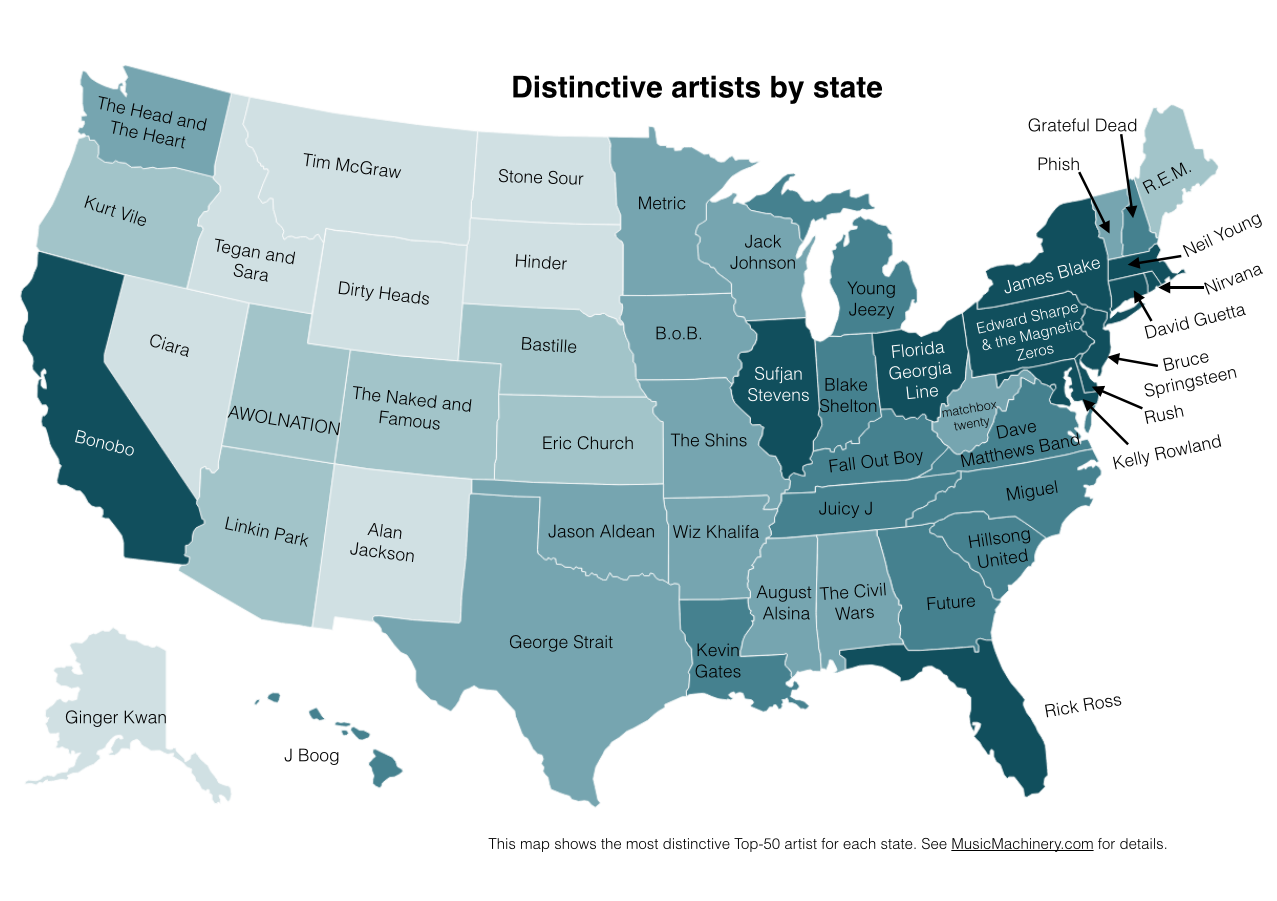
This is the previously published map that shows the artists that are listened to proportionally more frequently in a particular state than they are in all of the United States.
The data for both maps is drawn from an aggregation of data across a wide range of music services powered by The Echo Nest and is based on the listening behavior of a quarter million online music listeners.
It is interesting to see that even when we consider just the most popular artists, we can see regionalisms in listening preferences. I’ve highlighted the regions with color on this version of the map:
Favorite Artist Regions
Creative hacking
My hack at the MIDEM Music Hack Day this year is what I’d call a Creative Hack. I built it, not because it answered any business use case or because it demonstrated some advanced capability of some platform or music tech ecosystem, I built it because I was feeling creative and I wanted to express my creativity in the best way that I can which is to write a computer program. The result is something I’m particularly proud of. It’s a dynamic visualization of the song Burn by Ellie Goulding. Here’s a short, low-res excerpt, but I strongly suggest that you go and watch the full version here: Cannes Burn
[youtube http://www.youtube.com/watch?v=Fys0RGi3kA8&feature=youtu.be]Unlike all of the other hacks that I’ve built, this one feels really personal to me. I wasn’t just trying to solve a technical problem. I was trying to capture the essence of the song in code, trying to tell its story and maybe even touch the viewer. The challenge wasn’t in the coding it was in the feeling.
After every hack day, I’m usually feeling a little depressed. I call it post-hacking depression. It is partially caused by being sleep deprived for 48 hours, but the biggest component is that I’ve put my all into something for 48 hours and then it is just over. The demo is done, the code is checked into github, the app is deployed online and people are visiting it (or not). The thing that just totally and completely took over my life for two days is completely gone. It is easy to reflect back on the weekend and wonder if all that time and energy was worth it.
Monday night after the MIDEM hack day was over I was in the midst of my post-hack depression sitting in a little pub called Le Crillon when a guy came up to me and said “I saw your hack. It made me feel something. Your hack moved me.”
Cannes Burn won’t be my post popular hack, nor is it my most challenging hack, but it may be my favorite hack because I was able to write some code and make somebody that I didn’t know feel something.
New Genre APIs
Posted by Paul in code, Music, The Echo Nest, web services on January 16, 2014
 Today at the Echo Nest we are pushing out an update to our Genre APIs. The new APIs lets you get all sorts of information about any of over 800 genres including a description of the genre, representative artists in the genre, similar genres, and links to web resources for the genre (such as a wikipedia page, if one exists for a genre). You can also use the genres to create various types of playlists. With these APIs you build all sorts of music exploration apps like Every Noise At Once, Music Popcorn and Genre-A-Day.
Today at the Echo Nest we are pushing out an update to our Genre APIs. The new APIs lets you get all sorts of information about any of over 800 genres including a description of the genre, representative artists in the genre, similar genres, and links to web resources for the genre (such as a wikipedia page, if one exists for a genre). You can also use the genres to create various types of playlists. With these APIs you build all sorts of music exploration apps like Every Noise At Once, Music Popcorn and Genre-A-Day.
The new APIs are quite simple to use. Here are a few python examples created using pyen.
List all of the available genres with a description
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import pyen | |
| en = pyen.Pyen() | |
| response = en.get('genre/list', bucket=['description']) | |
| for g in response['genres']: | |
| print g['name'], '-', g['description'] |
This outputs text like so:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| a cappella – A cappella is singing without instrumental accompaniment. From the Italian for "in the manner of the chapel," a cappella may be performed solo or by a group. | |
| abstract hip hop – | |
| acid house – From house music came acid house, developed in the mid-'80s by Chicago DJs experimenting with the Roland TB-303 synthesizer. That instrument produced the subgenre's signature squelching bass, used to create a hypnotic sound. | |
| acid jazz – Acid jazz, also called club jazz, is a style of jazz that takes cues from a number of genres, including funk, hip-hop, house, and soul. | |
| … |
We can get the top artists for any genre like so:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import pyen | |
| import sys | |
| en = pyen.Pyen() | |
| if len(sys.argv) > 1: | |
| genre = ' '.join(sys.argv[1:]) | |
| response = en.get('genre/artists', name=genre) | |
| for artist in response['artists']: | |
| print artist['name'] | |
| else: | |
| print "usage: python top_artists_for_genre.py genre name" |
Here are the top artists for ‘cool jazz’
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| % python top_artists_for_genre.py cool jazz | |
| Thelonious Monk | |
| Stan Getz | |
| Lee Konitz | |
| The Dave Brubeck Quartet | |
| Bill Evans | |
| Cannonball Adderley | |
| Art Pepper | |
| Charlie Parker | |
| John Coltrane | |
| Gil Evans | |
| Ahmad Jamal | |
| Miles Davis | |
| Horace Silver | |
| Dave Brubeck | |
| Oliver Nelson |
We can find similar genres to any genre with this bit of code:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import pyen | |
| import sys | |
| en = pyen.Pyen() | |
| if len(sys.argv) > 1: | |
| genre = ' '.join(sys.argv[1:]) | |
| response = en.get('genre/similar', name=genre) | |
| for genre in response['genres']: | |
| print genre['name'] | |
| else: | |
| print "usage: python sim_genres.py genre name" |
Sample output:
% python sim_genres.py cool jazz bebop jazz hard bop contemporary post-bop soul jazz big band jazz christmas stride jazz funk jazz fusion avant-garde jazz free jazz
We can use the genres to create excellent genre playlists. To do so, create a playlist of type ‘genre-radio’ and give the genre name as a seed. We’ve also added a new parameter called ‘genre_preset’ that, if specified will control the type of songs that will be added to the playlist. You can chose from core, in_rotation, and emerging. Core genre playlists are great for introducing a new listener to the genre. Here’s a bit of code that generates a core playlist for any genre:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import pyen | |
| import sys | |
| en = pyen.Pyen() | |
| if len(sys.argv) < 2: | |
| print 'Usage: python genre_playlist.py seed genre name' | |
| else: | |
| genre = ' '.join(sys.argv[1:]) | |
| response = en.get('playlist/static', type='genre-radio', genre_preset='core-best', genre=genre) | |
| for i, song in enumerate(response['songs']): | |
| print "%d %s by %s" % ((i +1), song['title'], song['artist_name']) |
The core classic rock playlist looks like this:
- Simple Man by Lynyrd Skynyrd
- Born To Be Wild by Steppenwolf
- All Along The Watchtower by Jimi Hendrix
- Kashmir by Led Zeppelin
- Sunshine Of Your Love by Cream
- Let’s Work Together by Canned Heat
- Gimme Shelter by The Rolling Stones
- It’s My Life by The Animals
- 30 Days In The Hole by Humble Pie
- Midnight Rider by The Allman Brothers Band
- The Joker by Steve Miller Band
- Fortunate Son by Creedence Clearwater Revival
- Black Betty by Ram Jam
- Heart Full Of Soul by The Yardbirds
- Light My Fire by The Doors
The ‘in rotation’ classic rock playlist looks like this:
- Heaven on Earth by Boston
- Doom And Gloom by The Rolling Stones
- Little Black Submarines by The Black Keys
- I Gotsta Get Paid by ZZ Top
- Fly Like An Eagle by Steve Miller Band
- Blue On Black by Kenny Wayne Shepherd
- Driving Towards The Daylight by Joe Bonamassa
- When A Blind Man Cries by Deep Purple
- Over and Over (Live) by Joe Walsh
- The Best Is Yet To Come by Scorpions
- World Boss by Gov’t Mule
- One Way Out by The Allman Brothers Band
- Corned Beef City by Mark Knopfler
- Bleeding Heart by Jimi Hendrix
- My Sharona by The Knack
While the emerging ‘classic rock’ playlist looks like this:
- If You Were in Love by Boston
- Beggin’ by Shocking Blue
- Speak Now by The Answer
- Mystic Highway by John Fogerty
- Hell Of A Season by The Black Keys
- No Reward by Gov’t Mule
- Pretty Wasted by Tito & Tarantula
- The Battle Of Evermore by Page & Plant
- I Got All You Need by Joe Bonamassa
- What You Gonna Do About Me by Buddy Guy
- I Used To Could by Mark Knopfler
- Wrecking Ball by Joe Walsh
- The Circle by Black Country Communion
- You Could Have Been a Lady by April Wine
- 15 Lonely by Walter Trout
The new Genre APIs are really quite fun to use. I’m looking forward to seeing a whole new world of music exploration and discovery apps built around these APIs.
Learn about a new genre every day
Posted by Paul in code, genre, playlist, The Echo Nest on January 16, 2014
The Echo Nest knows about 800 genres of music (and that number is growing all the time). Among those 800 genres are ones that you already know about, like ‘jazz’,’rock’ and ‘classical’. But there are also hundreds of genres that you’ve probably never heard of. Genres like Filthstep, Dangdut or Skweee. Perhaps the best way to explore the genre space is via Every Noise at Once (built by Echo Nest genre-master Glenn McDonald). Every Noise At Once shows you the whole genre space, allowing you to explore the rich and varied universe of music. However, Every Noise at Once can be like drinking Champagne from a firehose – there’s just too much to take in all at once (it is, after all, every noise – at once). If you’d like to take a slower and more measured approach to learning about new music genres, you may be interested in Genre-A-Day.
Genre-A-Day is a web app that presents a new genre every day. Genre-A-Day tells you about the genre, shows you some representative artists for the genre, lets you explore similar genres, and lets you listen to music in the genre.
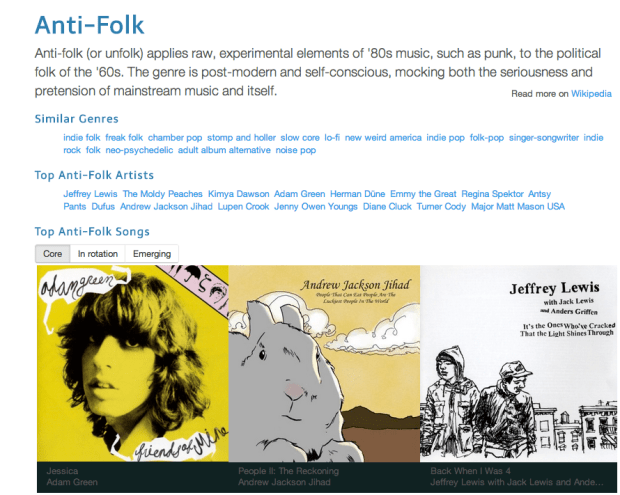
If you spend a few minutes every day reading about and listening to a new genre, after a few months you’ll be a much more well-rounded music listener, and after a few years your knowledge of genres will rival most musicologists’.
An easy way to make Genre-A-Day part of your daily routine is to follow @GenreADay on twitter. GenreADay will post a single tweet, once a day like so:
Under the hood – Genre-A-Day was built using the just released genre methods of The Echo Nest API. These methods allow you to get detailed info on the set of genres, the top artists for the genres, similar genres and so on. It also uses the super nifty genre presets in the playlist API that allow you to craft the genre-radio listener for someone who is new to the genre (core), for someone who is a long time listener of the genre (in rotation), or for someone looking for the newest music in that genre (emerging). The source code for Genre-A-Day is on github.
Six Degrees of Black Sabbath (v2)
Posted by Paul in code, fun, Music, The Echo Nest on January 6, 2014
For my Christmas vacation programming project this year, I revisited an old hack: Six Degrees of Black Sabbath. I wrote the original, way back in 2010 at the very first San Francisco Music Hack Day. That version is still up and running, and getting regular visits, but it is getting a bit long in the tooth and so I’ve given it a total rewrite from the ground up. The result is the new Six Degrees of Black Sabbath:

Six Degrees of Black Sabbath is like the Oracle of Bacon but for music. It lets you find connections to just about any two artists based upon their collaborations. Type in the name of two artists, and 6dobs will give you a pathway showing the connections that will get you from one artist to another. For instance, if you enter ‘The Beatles’ and ‘Norah Jones’ you’ll get a path like:
- We start with The Beatles
- The Beatles had member George Harrison
- George Harrison performed with Ravi Shankar on the song Bangla Dhun and 26 others.
- Ravi Shankar was parent of Norah Jones
If you don’t like a particular connection, you can bypass it generating a new path. For instance, if we bypass Ravi Shankar, it will take us eight steps to get to Norah Jones from the Beatles:
The Beatles -> Paul McCartney -> The Fireman -> Youth -> Pigface
-> Mike Dillon ->Garage A Trois -> Charlie Hunter -> Norah Jones
Not all connections are created equal. Mick Jagger and Keith Richards have been playing together for over 50 years in the Rolling Stones. That’s a much stronger connection than the one between Mick Jagger and Fergie for performing a single song together at the Rock and Roll Hall of Fame. We take these connection strengths into account when finding paths between artists. Preference is given to stronger connections, even if those stronger connections will yield a longer path.
The new version of Six Degrees of Black Sabbath has a number of new features:
Video – Each step in a path is represented by a Youtube video – often with a video by the two artists that represent that step. I’m quite pleased at how well the video works for establishing the connection between two artists. Youtube seems to have it all.

Live stats – The app tracks and reports all sorts of things such as the longest path discovered so far, the most frequently occurring artists on paths, the most connected artists, most searched for artists and so on.
Larger database of connections – the database has about a quarter million artists and 2.5 million artist-to-artist connections.
Autocomplete for artist names – no need to try to remember how to spell ‘Britney Spears‘ – just start typing the parts you know and it will sort it out.
Spiffier looking UI – It still looks like it was designed by an engineer, but at least it looks like it was designed in this decade by an engineer.
Path finding improvements – faster and better paths throughout.
Revisiting this app after 4 years was a lot of fun. I got to dive deep into a bunch of tech that was new to me including Redis, Bootstrap 3, and the YouTube video search API. I spent many hours untangling the various connections in the new Musicbrainz schema. I took a tour through a number of Pythonic network graph libraries (Networkx, igraph and graph-tool), I learned a lot about Python garbage collection when you have a 2.5gb heap.
Give the app a try and let me know what you think.
Million Song Shuffle
 Back in 2001 when the first iPod was released, Shuffle Play was all the rage. Your iPod had your 1,000 favorite songs on it, so picking songs at random to play created a pretty good music listening experience. Today, however, we don’t have 1,000 songs in our pocket. With music services like Rdio, Rhapsody or Spotify, we are walking around with millions of songs in our pocket. I’ve often wondered what it would be like to use Shuffle Play when you have millions of songs to shuffle through. Would it be a totally horrible listening experience listening to artists that are so far down the long tail that they don’t even know that they are part of a dog? Would you suffer from terminal iPod whiplash as you are jerked between Japanese teen pop and a John Philip Sousa march?
Back in 2001 when the first iPod was released, Shuffle Play was all the rage. Your iPod had your 1,000 favorite songs on it, so picking songs at random to play created a pretty good music listening experience. Today, however, we don’t have 1,000 songs in our pocket. With music services like Rdio, Rhapsody or Spotify, we are walking around with millions of songs in our pocket. I’ve often wondered what it would be like to use Shuffle Play when you have millions of songs to shuffle through. Would it be a totally horrible listening experience listening to artists that are so far down the long tail that they don’t even know that they are part of a dog? Would you suffer from terminal iPod whiplash as you are jerked between Japanese teen pop and a John Philip Sousa march?
To answer these questions, I built an app called Million Song Shuffle. This app will create a playlist by randomly selecting songs from a pool of many millions of songs. It draws from the Rdio collection and if you are an Rdio user you can hear listen to the full tracks.
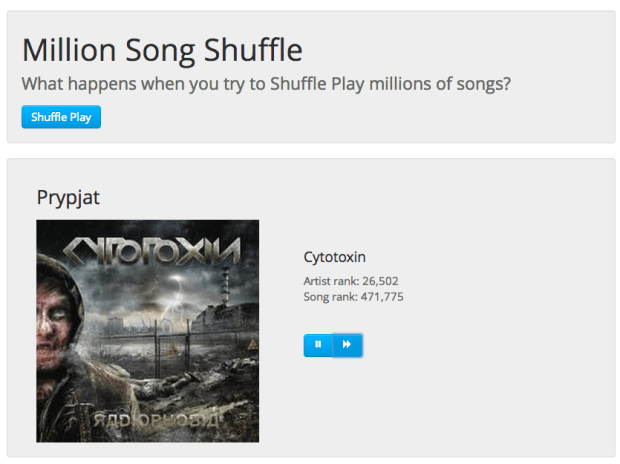
The app also takes advantage of a nifty new set of data returned by the Echo Nest API. It shows you the absolute hotttnesss rank for the song and the artist, so you will always know how deep you are into the long tail (answer: almost always, very deep).
So how is listening to millions of songs at random? Surprisingly, it’s not too bad. The playlist certainly gets a high score for eclecticism and surprise, and most of the time the music is quite listenable. But give it a try, and form your own opinion.
Its fun, too, to see how long you can listen to the Million Song Shuffle before you encounter a song or even an artist that you’ve heard of before. If the artist is not in the top 5K artists, it is likely you’ve never heard of them. After listening to Million Song Shuffle for a little while you start to get an idea of how much music there is out there. There’s a lot.
For the ultimate eclectic music listening experience, try the Million Song Shuffle.
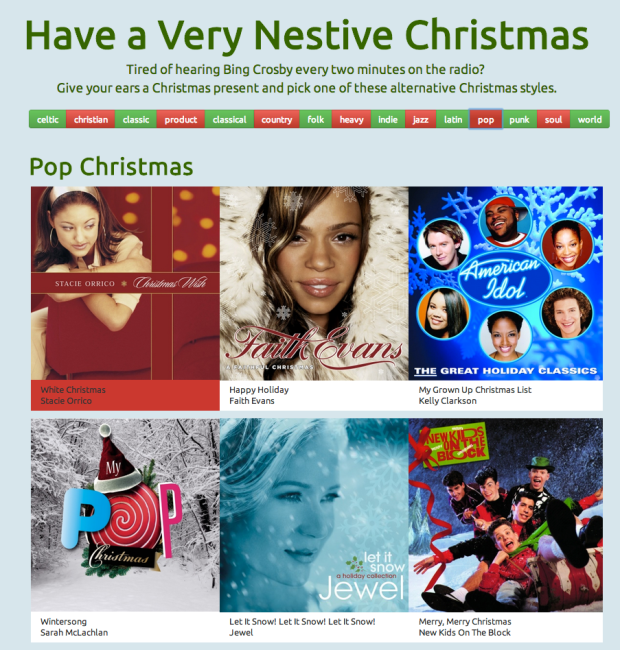
Have a Very Nestive Christmas
Posted by Paul in code, Music, playlist, The Echo Nest on December 19, 2013
We are approaching peak Christmas music season. That means that many of us are getting really sick of hearing the same Christmas songs over and over. One can only hear Bing Crosby’s White Christmas so many times before measures must be taken. To remedy this situation, this morning I created a quick web app that let you chose from among a number of different Christmas genres (from classical to heavy metal) to let you add a little variety to your Christmas mix. If you are getting weary of the Christmas standards, but still want to listen to Christmas music, you may want to give it a try: The Christmas Playlister